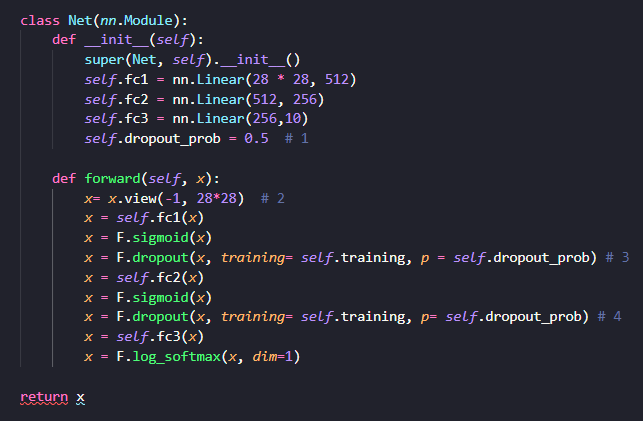
[예제 3-1] Dropout
- #1 : 몇 퍼센트의 노드에 대해 가중값을 계산하지 않을 것인지 명시
- #2 : 2차원 데이터를 1차원 데이터로 변환(MLP 모델은 1차원 벡터 값을 입력 받을 수 있음
#3, #4
- 각 sigmoid() 함수의 결괏값에 대해 Dropout 적용
- p = 몇 퍼센트의 노드에 대해 계산하지 않을 것인지 조정
- training = self.training -> 학습상태와 검증상태에 따라 다르게 적용하기 위해 존재
- model.train()을 명시할 때 self.training = True , model.eval()을 명시할 때 self.training = False 적용
- 이론상 Dropout을 적용했을 때 일반화가 강해져 Test Accuracy가 높아지는 결과가 기대
- But, 이는 학습 데이터셋과 검증 데이터셋의 피처 및 레이블의 분포 간 많은 차이가 있을 때 유효
- Epoch을 늘려 추가로 학습을 진행하면 성능이 좋아지는 경향
- Dropout은 보통 ReLU() 비선형 함수와 잘 어우
[예제 3-2] Dropout + ReLU
- ReLU -> Gradient을 빠르게 계산하고 Back Propagation을 효과적으로 이용
- x = F.sigmoid(x) -> x = F.relu(x)로 변경

- sigmoid() 함수를 적용했을 때보다 ReLU() 함수를 적용했을 때 높은 성능 확인
[예제 3-3] Dropout + ReLU + Batch Normalization
- 배치 정규화 -> 각 Layer마다 Input의 분포가 달라짐에 따라 학습 속도가 현저히 느려지는 것을 방지
#1
- MLP 내 각 Layer에서 데이터는 1-Dimension 크기의 벡터 값 계산 -> nn.BactchNorm1d
- 첫 번째 Fully Connected Layer의 Output이 512 크기의 벡터 값
#2
- 두 번째 Fully Connected Layer의 Output이 256 크기의 벡터 값
#3
- 첫 번째 Fully Connected Layer의 Output을 'self.batch_norm1'의 Input으로 이용해 배치 정규화
#4
- 두 번째 Fully Connected Layer의 Output을 'self.batch_norm2'의 Input으로 이용해 배치 정규화

- Batch Normalization을 적용했을 때 Test Loss는 감소하며, Test Accuracy 값이 높아짐
[예제 3-4] Dropout + ReLU + Batch Normalization + He Uniform Initialization
- weight 초깃값 설정이 딥러닝 성능에 있어 매우 중요한 부분
#1
- Weight, Bias 등 딥러닝 모델에서 초깃값으로 설정되는 요소에 대한 모듈인 init 임포트
#2
- MLP 모델을 구성하고 있는 파라미터 중 nn.Linear에 해당하는 파라미터 값에 대해서만 지정
#3
- nn.Linear에 해당하는 파라미터 값에 대해 he_initialization을 이용해 파라미터값 초기화
- kaiming_uniform = he_initialization
#4
- weight_init 함수를 Net() 클래스의 인스턴스인 model에 적용해 파라미터 초기화

[예제 3-4] Dropout + ReLU + Batch Normalization + He Uniform Initialization+ Adam
- optimizer 정의는 단 한줄만 변경하면 됨
- Adam은 대체적으로 RMSProp + Momentum

'Study > DL' 카테고리의 다른 글
| [밑시딥1] Chapter 7. 합성곱 신경망(CNN) (1) | 2024.01.15 |
|---|---|
| [파이썬 딥러닝 파이토치] Part 4. Computer Vision-1 (0) | 2024.01.14 |
| [모두를 위한 딥러닝 시즌2] lab 9-1~9-4 (0) | 2024.01.12 |
| [밑시딥1] Chapter 6. 학습 관련 기술들 (0) | 2024.01.10 |
| [밑시딥1] Chapter 5. 오차역전파법 (0) | 2024.01.10 |



