fully-connected 계층(Affine 계층)으로 이뤄진 네트워크
- Affine 계층 뒤에 활성화 함수(ReLU, Softmax)

문제점
- 데이터의 형상이 무시
- ex) 3차원 -> 1차원 데이터로 평탄화해서 입력해줘야 함
CNN으로 이뤄진 네트워크
- '합성곱 계층(Conv)' 과 '풀링 계층(Pooling)' 이 추가
- Conv - ReLU -(Pooling) 흐름
- 출력에 가까운 층에서는 지금까지의 'Affine-ReLU' 구성 사용 가능(Input 데이터 Flatten 필수)
- 마지막 출력 계층에서는 'Affine-Softmax' 조합 그대로 사용(Input 데이터 Flatten 필수)

- 합성곱 계층의 입출력 데이터 : 특징 맵(featrue map)
- 합성곱 계층의 입력 데이터: 입력 특징 맵(input feature map)
- 합성곱 계층의 출력 데이터: 출력 특징 맵(output feature map)
장점
- 합성곱 계층은 데이터 형상을 유지(지역 정보 학습)
- ex) 3차원 데이터 입력 시 다음 계층에도 3차원 데이터 전달
- 그래서 CNN에서는 이미지처럼 형상을 가진 데이터를 제대로 이해할 가능성 O
2차원 데이터 합성곱 연산
- 이미지 처리에서 말하는 필터 연산
- 필터의 윈도우를 일정 간격으로 이동해가며 입력 데이터에 적용
- 입력과 필터에서 대응하는 원소끼리 곱한 후 총합(단일 곱셈-누산)
- CNN에서는 필터의 매개변수가 그동안의 '가중치'에 해당


- 편향은 필터를 적용한 후의 데이터에 더해짐
- 항상 (1x1)만 존재

패딩(padding) - ex) (4x4)
- 입력데이터 주위에 0을 채움
- 패딩 1 -> (6x6) , 패딩 2 -> (8x8) ....
- 입력 데이터의 공간적 크기를 고정한 채로 다음 계층에 전달하기 위한 목적
- 합성곱 연산을 거칠 때마다 크기가 작아져 출력 크기가 1이 되어 더 이상 합성곱 연산을 수행하지 못하는 것을 방지
- 가장자리에 있는 픽셀 값은 안쪽에 있는 픽셀 값보다 적게 Convolution 적용되는 것을 방지

스트라이드(stride)
- 필터를 적용하는 위치의 간격
- ex) 스트라이드 2 -> 필터를 적용하는 윈도우가 두 칸씩 이동
- 스트라이드를 키우면 출력 크기가 작아짐

Weight Sharing
- CNN 학습 시 기본적으로 학습해야 할 파라미터의 수가 매우 많음
- Weight 공유로 학습할 파라미터의 수를 최대한 줄임

- 출력 크기 구하는 식

3차원 데이터의 합성곱 연산
- 입력 데이터와 필터의 합성곱 연산을 채널마다 수행하고, 그 결과를 더해서 하나의 출력
- 입력 데이터의 채널 수 와 필터의 채널 수가 같아야 함 (필터 자체 크기 설정 가능)

블록으로 생각하기
- 채널 C, 높이 H, 너비 W
- 입력 데이터 (C,H,W)
- 필터 (C,FH,FW)
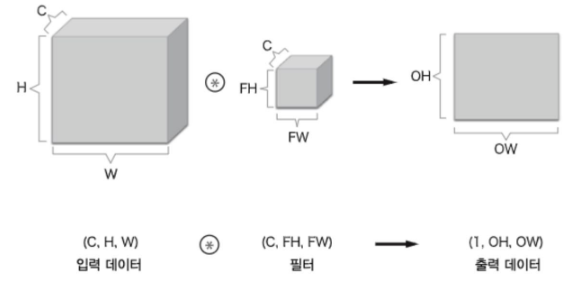
- 필터를 FN개 적용하면 출력 맵도 FN개 생성 (필터의 가중치 데이터 = 4차원)
- FN개의 맵을 모으면 (FN,OH,OW) 블록 완성
- 편향은 채널 하나에 값 하나 (FN,1,1)

배치 처리
- 입력 데이터 차원을 하나 늘려 4차원 데이터로 저장
- (데이터 수, 채널 수 , 높이, 넢이)
- N회 분의 처리를 한 번에 수행

풀링 계층
- 세로, 가로 방향의 공간을 줄이는 연산(CNN 학습 속도 향상 목적)
- 정보 손실 불가피 (최근에는 최대한 정보+속도향상 알고리즘 개발로 Pooling Layer 사용하지 않은 경우 O)
- 최대 풀링 : 최대값을 구하는 연산
- 2x2 : 대상 영역의 크기
- 스타라이드 2 : 2x2 윈도우가 원소 2칸 간격으로 이동

- 학습해야 할 매개변수 X
- 채널 수 변하지 X
- 입력의 변화에 영향을 적게 받음
*Convolution의 Receptive Field의 크기, Stride, Pooling의 종류, Layer를 쌓는 횟수 등
-> 모두 사용자가 지정해야 되는 하이퍼파라미터
CNN 시각화하기
- CNN을 구성하는 합성곱 계층은 입력으로 받은 이미지 데이터에서 '무엇을 보고 있는' 걸까?
1번째 층의 가중치 시각화
- 학습 전 필터는 무작위로 초기화되고 있어 흑백 정도에 규칙성 X
- 한편, 학습을 마친 필터는 규칙성 있는 이미지
- 오른쪽 같이 규칙성 있는 필터는 '무엇을 보고 있는' 걸까?

- 그것은 에지(색상이 바뀐 경계선)와 블롭(국소적으로 덩어리진 영역) 등을 보고 있음
- 왼쪽 절반이 흰색이고 오른쪽 절반이 검은색인 필터 1은 세로 방향의 에지에 반응
- 위쪽이 검은색이고, 아래쪽이 흰색인 필터 2는 가로 방향의 에지에 반응

층 깊이에 따른 추출 정보 변환
- 1번째 층의 합성곱 계층에서는 에지나 블롭 등의 저수준 정보가 추출
- 계층이 깊어질수록 추출되는 정보는 더 추상화
- 즉, 사물의 '의미'를 이해하도록 변화한 것
- 층이 깊어지면서 뉴런이 반응하는 대상이 단순한 모양에서 '고급' 정보로 변화

대표적인 CNN
LeNet
- 손글씨 숫자를 인식하는 네트워크
- 합성곱 계층과 풀링 계층을 반복(단순히 '원소를 줄이기만'만 하는 서브샘플링 계층)하여 완전연결 계층거쳐 출력
- 시그모이드 함수 사용(현재는 주로 ReLU 사용)
- 서브샘플링을 하여 중간 데이터 크기 줄임(현재는 최대 풀링이 주류)

AlexNet
- 딥러닝 열풍을 일으키는 데 큰 역할
- LeNet에서 큰 구조는 바뀌지 않음
- But, 활성화 함수로 ReLU 사용
- But ,LRN(Local Response Normalization)이라는 국소적 정규화를 실시하는 계층 이용
- But, 드롭아웃 사용

- LeNet 과 AlexNet에 큰 차이가 없지만 빅데이터와 GPU가 딥러닝 발전에 크게 기여
'Study > DL' 카테고리의 다른 글
| [밑시딥1] Chapter 8. 딥러닝 (0) | 2024.01.18 |
|---|---|
| [모두를 위한 딥러닝 시즌2] lab 10-2. MNIST CNN (0) | 2024.01.15 |
| [파이썬 딥러닝 파이토치] Part 4. Computer Vision-1 (0) | 2024.01.14 |
| [파이썬 딥러닝 파이토치] Part 3. Deep Learning (0) | 2024.01.12 |
| [모두를 위한 딥러닝 시즌2] lab 9-1~9-4 (0) | 2024.01.12 |



