- 최적화 : 손실 함수의 값을 가능한 한 낮추는 매개변수의 최적값을 찾는 문제를 푸는 것
[SGD의 단점]


- 해당 함수의 기울기 = y축 방향은 가파른데 x축 방향은 완만
- 기울기 대부분은 최솟값 (x,y) = (0,0) 방향을 가리키지 X

- 해당 함수에 SGD 적용
- 상당히 비효율적인 움직임
- 즉, 비등방성 함수에선은 탐색 경로가 비효율적 (방향에 따라 기울기가 달라지는 함수)
*가장 가파르게 내려가는 방향은 수직 방향!

[모멘텀(Momentum)]
*Gradient 누적함으로써 관성을 가지게 됨
- v = 속도
- αv = 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할(α는 0.9등의 값으로 설정)
- 기울기 방향으로 힘을 받아 물체가 가속된다는 물리법칙
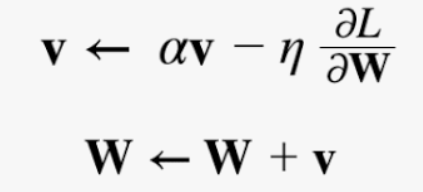
- local minimum에서 빠져나올 수 있음
- But, 큰 폭으로 인해 global minimum 도달 못할 가능성 O

- SGD와 비교하면 '지그재그 정도'가 덜함
- x축의 힘은 아주 작지만 방향은 변하지 않아서 한 방향으로 일정하게 가속
- y축의 힘은 크지만 위아래로 번갈아 받아서 상충하여 y축 방향의 속도는 안정적이지 X

[AdaGrad]
- 개별 매개변수에 적응적으로 학습률 조정하면서 학습 진행
- h = 기존 기울기 값을 제곱하여 계속 더함
- 매개변수의 원소 중에서 많이 움직인 원소는 학습률이 낮아짐

- Momentum 단점 보완
- But, 학습이 오래 진행되면 학습률이 너무 작아져서 모델의 학습이 거의 이루어지지 않는 상황이 발생할 수 있음

- y축 방향은 기울기가 커서 처음에는 크게 움직이지만, 그 큰 움직임에 비례해 갱신 정도도 큰 폭으로 작아짐
- y축 방향으로 갱신 강도가 빠르게 약해지고, 지그재그 움직임이 줄어듦

[Adam]
- 직관적으로 Momentum + Adagrad 융합한 기법
- 하이퍼파리미터의 '편향 보정'이 진행

- 가중치 감소 기법 : 오버비팅을 억제해 범용 성능을 높이는 테크닉
[가중치의 초깃값을 0으로 하면 안되는 이유]
- 순전파 때 입력층의 가중치 0이면 두 번째 층의 뉴런에 모두 같은 값이 전달
- 역전파 때 두 번째 층의 가충치가 모두 똑같이 갱신
- 이는 가중치를 여러 개 갖는 의미가 사라짐
- 즉, 초기값을 무작위로 설정해야 함
[은닉층의 활성화값 분포]
가중치를 표준편차가 1인 정규분포로 초기화할 때의 각 층의 활성화값 분포(시그모이드 함수)
- 0과 1에 치우쳐 분포
- 시그모이드 함수는 그 출력이 0에 가까워지자(또는 1에 가까워지자) 그 미분은 0에 다가감
- 결국 역전파의 기울기 값이 점점 사라짐(기울기 소실)
가중치를 표준편차가 0.01인 정규분포로 초기화할 때의 각 층의 활성화값 분포(시그모이드 함수)
- 0.5 부근에 집중 (기울기 소실 문제 X)
- But, 활성화 값들이 치우침 -> 다수의 뉴런이 거의 같은 값을 출력하여 뉴런을 여러 개 둔 의미 X
- 표현력 제한

[Xavier 초깃값] - 활성화 값들을 광범위하게 분포시킬 목적
- 초깃값의 표준편차가 1/√n이 되도록 설정(n은 앞 층의 노드 수)
- 앞 층에 노드가 많을수록 대상 노드의 초깃값으로 설정하는 가중치가 좁게 퍼짐

- Xavier 초깃값은 활성화 함수가 선형인 것을 전제
- sigmoid와 tanh 함수는 좌우 대칭이라 중앙 부근이 선형인 함수로 볼 수 있음
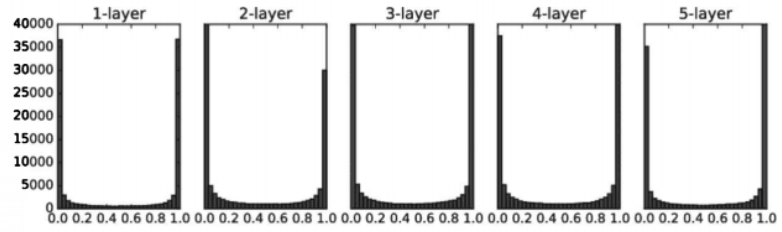
[ReLU를 사용할 때의 가중치 초깃값]
- He 초깃값
- 앞 계층 노드가 n개일 때, 표준편차가 √ 2/n 인 정규분포 사용
- std = 0.01일 때의 각 층의 활성화 값들을 아주 작은 값
- 역전파 때 가중치의 기울기 역시 작아진다는 뜻 -> 학습이 거의 이루어지지 X
- Xavier 초기값 결과를 보면 층이 깊어지면서 치우침이 조금씩 커짐
- 기울기 소실 문제

- He 초깃값은 모든 층에서 균일하게 분포

장점
- 학습 속도 개선
- 초깃값에 크게 의존하지 않는다
- 오버피팅 억제
- 데이터 분포가 평균이 0, 분산이 1이 되도록 정규화
- '배치 정규화 계층'을 활성화 함수의 앞(혹은 뒤)에 삽입함으로써 데이터 분포가 덜 치우게 함

- (미니배치) m개의 입력 데이터의 집합에 대해 평균과 분산을 구함
- ε 기호는 작은 값(예컨대 10e-7 등)으로 0으로 나누는 사태를 예방

- 배치 정규화 계층마다 이 정규화된 데이터에 고유한 확대와 이동 변환 수행
- : 확대 , : 이동
- 처음에는 γ =1, β=0 부터 시작하고, 학습하면서 적합한 값 조정


- 배치 정규화를 이용하지 않은 경우엔 초기값이 잘 분포되어 있지 않으면 학습 전혀 진행되지 않은 경우O

오버피팅은 주로 다음의 두 경우에 일어남
- 매개변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적음
[가중치 감소]
- 오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우 많음
- 가중치의 제곱 노름을 손실 함수에 더함
- λ = 정규화의 세기를 조절하는 하이퍼파라미터
- 1/2 = 미분의 결과인 λW를 조정하는 역할
- 오차역전파법에 따른 결과에 정규화 항을 미분한 를 더함

- λ = 0.1 가중치 감소 적용
- 훈련 데이터와 시험 데이터의 정확도 차이가 줄어듦(overfitting 억제)
- 단, 훈련데이터 정확도 100% 도달 X

[드롭아웃]
- 훈련 때 은닉층의 뉴런을 무작위로 골라 삭제
- 시험 때는 모든 뉴런에 신호를 전달 (단, 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱합)

- overfitting 억제 (단, 훈련데이터 정확도 100% 도달 X)

* 드롭아웃은 앙상블 학습과 밀접
- 학습할 때 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해석
- 추론 때는 뉴런의 출력에 삭제한 비율을 곱함으로써 앙상블 학습에서 여러 모델의 평균을 내는 것과 같은 효과
[검증 데이터 필요성]
- 시험 데이터를 사용하여 하이퍼파리미터 조정하면 하이퍼파라미터 값이 시험 데이터에 오버피팅
- 하이퍼파리미터 전용 확인 데이터 필요 = 검증 데이터
[하이퍼파라미터 최적화]
- 핵심 = 하이퍼파라미터의 '최적 값'이 존재하는 범위를 조금씩 줄여간다는 것
- grid search보다 무작위로 샘플링해 탐색하는 편이 좋은 결과를 낸다고 알려져 있음
[정리]
- 매개변수 갱신 방법에는 확률적 경사 하강법(SGD) 외에도 모멘텀,AdaGrad, Adam 등이 있음
- 가중치의 초깃값을 정하는 방법은 올바른 학습을 하는 데 매우 중요
- 가중치의 초깃값으로는 'Xavier 초깃값'과 'He 초깃값'이 효과적
- 배치 정규화를 이용하면 학습을 빠르게 진행할 수 있으며, 초깃값의 의존도가 덜함
- 오버피팅을 억제하는 정규화 기술로는 가중치 감소와 드롭아웃이 있음
- 하이퍼파라미터 값 탐색은 최적 값이 존재할 법한 범위를 점차 좁히면서 하는 것이 효과적임
'Study > DL' 카테고리의 다른 글
| [파이썬 딥러닝 파이토치] Part 3. Deep Learning (0) | 2024.01.12 |
|---|---|
| [모두를 위한 딥러닝 시즌2] lab 9-1~9-4 (0) | 2024.01.12 |
| [밑시딥1] Chapter 5. 오차역전파법 (0) | 2024.01.10 |
| [밑시딥1] Chapter 4. 신경망 학습 (1) | 2024.01.09 |
| [밑시딥1] Chapter 3. 신경망 (3) | 2024.01.09 |



