[9-1]
시그모이드의 문제점
- 출력이 0에 가까워지자(또는 1에 가까워지자) 그 미분은 0에 다가감

- 0에 가까운 기울기가 곱해질 경우 역전파의 기울기 값이 점점 사라짐 (기울기 소실)

- 이를 보완하고자 ReLU 함수가 나옴
- 입력값이 0을 넘을 때 기울기 = 1
- 음수의 영역에서는 기울기가 0이어서 음수로 activation 될 경우 기울기가 사라질 위험이 있으나 그래도 잘 동작

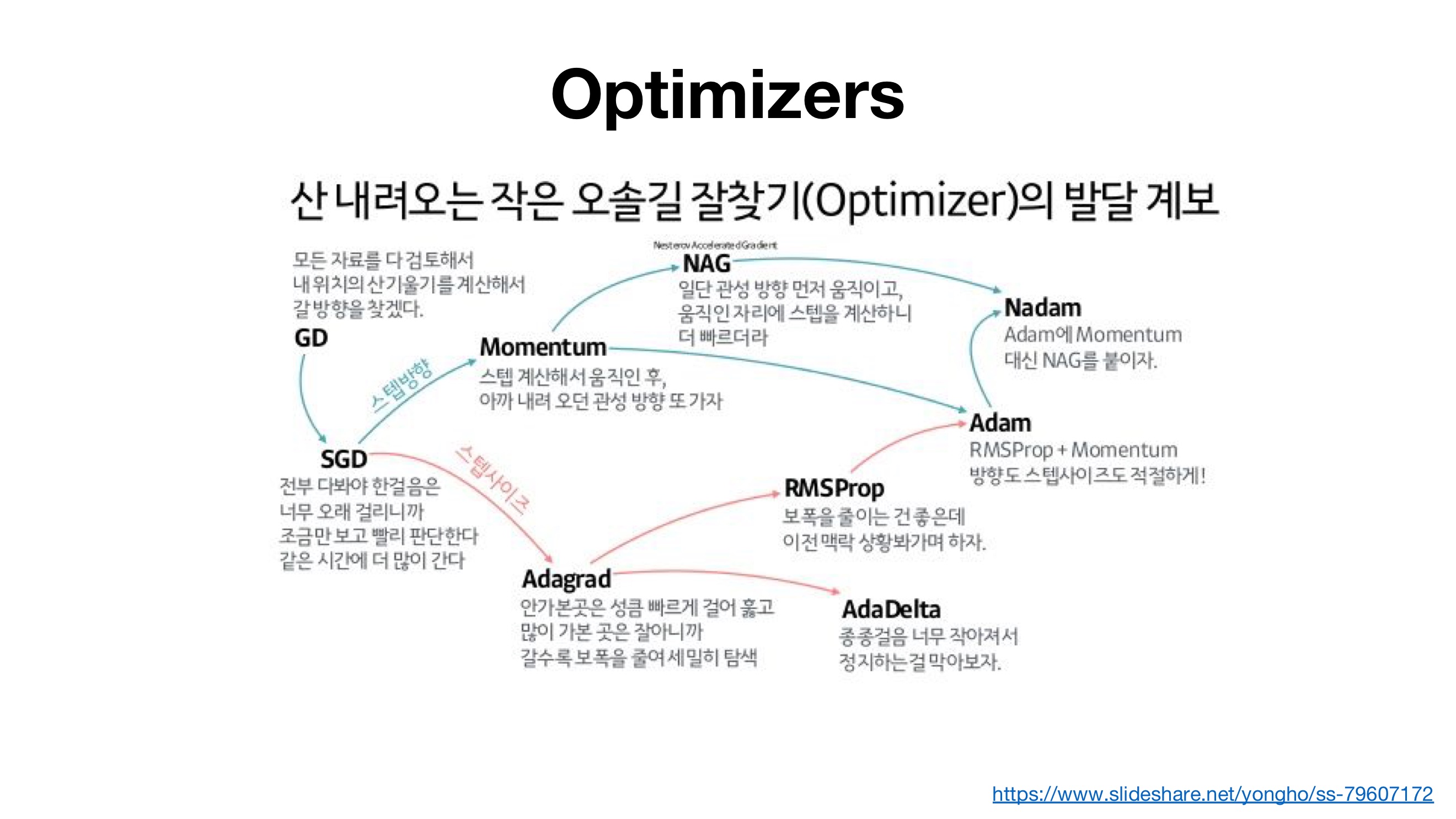




[9-2]
- N -> weight initialization 적용 (훨씬 더 성능이 좋음)
- weight 초깃값 설정이 딥러닝 성능에 있어 매우 중요한 부분

- IF, 가중치 초깃값을 0으로 설정할 경우 모든 gradient 값이 0이기에 학습할 수 X
[RBM (Restricted Boltzmann machine)]
- 같은 layer에 있는 node끼리는 연결하지 X
- 다른 layer끼리 fully connection
- Pre-training 과 Fine-tuning 과정을 거쳐 initialize를 하는 초창기 모델(잘 사용 X)


[Xavier / He initialization]
- layer의 특성에 따라 initialization
- Normal initialization / Uniform initialization 모델 존재
- nin : layer의 input 수
- nout: layer의 output 수
- He는 Xavier와 달리 nout값이 존재하지 않는 모델

- fan_in = nin
- fan_out = nout

- Xavier 함수는 nn.init 패키지에 있음


9-3
- Underfitting -> 너무 낮은 차원의 모델 사용
- Overfitting -> 너무 높은 차원의 모델 사용


- Overfitting 모델은 train data에 대해 매우 높은 정확도를 보임
- But, test data에 대해서는 정확도가 떨어지고 에러율 증가

[Dropout]
- 모델의 일부 뉴런을 랜덤하게 제거하고, 학습을 진행하여 Overfitting 방지
* Dropout ≒ 앙상블 학습
1. 매 학습때 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해석
2. 추론 때는 뉴런의 출력에 삭제한 비율을 곱합으로써 앙상블 학습에서 여러 모델의 평균을 내는 것과 같은 효과

- (p=drop_prob) 학습을 하면서 해당 스텝마다 전체 노드 중에 몇퍼센트 정도를 사용 안 할지 결정

- test 시에는 모든 뉴런에 신호 전달 (Dropout X)
- model.train() : Dropout 적용 -> train 전에 선언
- model.eval(): Dropout 적용 X -> test 전에 선언

9-4
- Gradient Vanishing : 기울기 소실
- Gradient Exploding : 기울기 폭주

- Train과 Test 데이터의 분포 차이가 문제를 일으킴( ≒ 입력과 출력 분포가 다름)

- Layer 들끼리 Covariate Shift가 발생

[Batch Normalization]
- 각 Layer 데이터 분포가 평균이 0, 분산이 1이 되도록 정규화
- (미니배치) m개의 입력 데이터의 집합에 대해 평균과 분산을 구함
- ε 기호는 작은 값(예컨대 10e-7 등)으로 0으로 나누는 사태를 예방
- 배치 정규화 계층마다 이 정규화된 데이터에 고유한 확대와 이동 변환 수행(: 확대 , : 이동)
- -> 이유: 연속적으로 Batch Normalization 시 activation 함수의 비선형성 손실을 완화
- 처음에는 γ =1, β=0 부터 시작하고, 학습하면서 적합한 값 조정

[Batch Normalization에서도 Train mode, Evaluation mode 사용]
- Batch Normalization 하는 과정에서 X가 변경되면 μ 와 variance가 전혀 다른 값이 나올 수 있음
- 즉, batch 값이 바뀌면다른 결과가 나올 수 있음
- 따라서 이 과정에서도 trian과 evaluation 모드를 따로 둠
learning mean 과 learning variance
- 학습셋에서 sample mean(= μ)과 sample variance(=σ) 평균을 따로 저장 (learning mean, learning variance)
- Inference (테스트)할 때 입력 데이터의 μ 와 variance가 아닌, leanring mean과 learning variance를 계산
- Batch Normalization 학습이 끝난 뒤 입력 batch 데이터와 상관 없이 변하지 않는 고정값이 됨
- 이 값을 inference 할 때에는 이 값을 이용하여 mean과 variance로 normalizae를 시키는 방식을 취함
- 따라서 , batch에 있는 데이터가 변하더라도 normalize하는 mean과 variance 값이 바뀌지 X
- normalization 기법은 activation 함수 이전에 사용하는 것이 일반적



'Study > DL' 카테고리의 다른 글
| [파이썬 딥러닝 파이토치] Part 4. CNN (0) | 2024.01.14 |
|---|---|
| [파이썬 딥러닝 파이토치] Part 3. Deep Learning (0) | 2024.01.12 |
| [밑시딥1] Chapter 6. 학습 관련 기술들 (0) | 2024.01.10 |
| [밑시딥1] Chapter 5. 오차역전파법 (0) | 2024.01.10 |
| [밑시딥1] Chapter 4. 신경망 학습 (1) | 2024.01.09 |



