Denoising Diffusion Probabilistic Models
논문 원본 : https://arxiv.org/abs/2006.11239
발표 영상 : https://www.youtube.com/watch?v=ASwSuJmMtts
Denoising Diffusion Probabilistic Models
We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound
arxiv.org
1. Abstract & Introduction
- 최근 다양한 유형의 Deep generative model이 여러 데이터 형태에서 높은 품질의 이미지와 오디오 샘플을 생성해왔음
- Generative Adversarial Networks (GAN), Variational Autoencoders (VAE), Flow-based models
GAN
- Generative model (G) Discriminative model (D)를 동시에 훈련시키는 방법 제안
- G는 training data의 분포를 모사 (D가 구별하지 못하도록) => 지폐 위조범
- D는 해당 데이터가 G가 만든 것인지, 원본인지 판별 => 경찰
- 즉, 두 모델은 서로 게임을 하듯이 경쟁하면서 학습 진행
VAE
- 입력이미지가 Encoder를 통과해 μ와 σ 벡터를 output
- μ와 σ 를 결합해서 정규분포 생성
- 정규분포에서 잠재변수 z를 샘플링
- z를 decoder에 입력하여 원래의 입력 이미지를 복원
- 입력데이터를 효율적으로 압축하고 복원하는 방법을 학습함으로써, 학습 데이터의 분포를 이해하고, 이 분포를 활용해 새로운 데이터를 생성할 수 있는 능력을 갖추게 됨
Flow-based generative models
- 가역함수 f(x)를 사용하여 입력데이터를 잠재공간으로 압축
- 역함수 f-1(z)를 통해 다시 원본 데이터로 복원
- 이러한 과정을 통해 입력 데이터 분포를 학습하여 x를 잘 표현하는 z를 만드는 f(x)를 학습하는게 목표

- 본 논문에서는 diffusion probabilistic models의 발전을 제시
Diffusion (확산)
- 물리 통계 동역학에 기초한 개념
- 액체나 기체에 다른 물질이 섞이고, 그것이 조금씩 고르게 번져나가 마지막엔 같은 농도로 바뀌는 현상
- 2015년 "Deep unsupervised learning using nonequilibrium themodynamics"에서 Diffusion을 최초로 딥러닝에 활용

Diffusion Probabilistic Models (= Diffusion model)
forward process (diffusion process)
- data에 gaussian noise를 추가하는 과정
- markov chain을 통해 점진적으로 noise를 추가
- markov chain : 현재 상태 xt는 이전 상태 xt-1를 기반으로 노이즈가 추가
reverse process
- gaussian noise에서 시작하여 점진적으로 noise를 제거하여 이미지를 복원하는 과정

- 학습 후에는, 무작위 노이즈에서 시작해 Reverse Process를 사용해 노이즈를 제거하면서 새로운 이미지 생성
2. Background
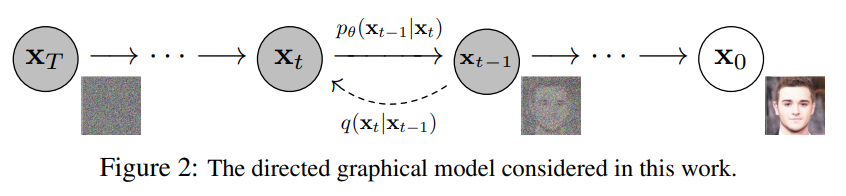
Forward Process (Diffusion Process)
- 원본 이미지에 x0에 대해 순차적으로 Gaussian Markov chain 적용
- 첫 번째 식 (왼쪽) : x1부터 xT까지 모든 단계에서 데이터 변화 전체 과정
- 첫 번째 식 (오른쪽) : Markov chain, 모든 단계를 곱하여 전체 변화를 설명
- 학습 대상 X (Gaussian noise 크기(βt)를 사전에 정의하기 때문)
- βt는 점진적으로 커지도록 설계 (Linear schedule, Quad schedule, Sigmoid schedule)
- 이때 noise를 추가할 때 데이터에 √1−βt 로 스케일(이전 단계의 데이터가 현재 단계에 얼마나 반영될지 조절)
- xT는 N(xT;0,I) => 모든 차원에서 동일한 분산을 가짐 (즉, 분산이 1)
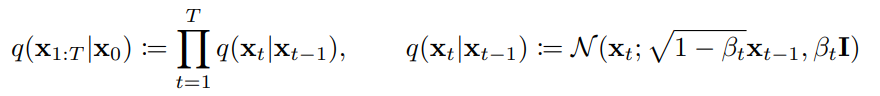
Reverse Process
- Gaussian noise xT에서 denoising 하면서 이미지 x0를 만드는 과정
- 1994년 논문에서 βt가 매우 작을 때 forward process가 Gaussian일 경우, reverse process도 Gaussian임을 증명
- 하지만 우리가 구하지 못하는 Gaussian 분포 => 학습 대상 O (μθ와
- 첫 번째 식(왼쪽) : 전체 Reverse Process, xT에서 시작하여 x0로 가는 모든 과정
- 첫 번째 식 (오른쪽) : p(xT)-> 노이즈화된 최종 상태, 뒷 부분 -> 각 단계에서 xt가 xt-1로 변환하는 과정을 모두 곱한 것
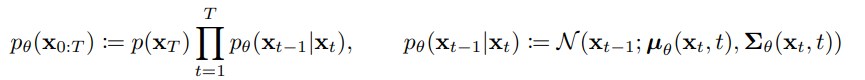
Loss Function
- LT : Regularization Loss (마지막 시간 단계 T에서의 noise 이미지 xT의 분포 q(xT|x0)가 사전에 정의된 노이즈 분포 p(xT)와의 차이를 최소화. 모델이 noise를 다루는 능력을 향상시켜, 원본 이미지를 잘 복원할 수 있도록 도움)
- L0 : Reconstruction Loss (x1로부 원래 이미지 x0을 재구성할 때 Loss. 즉, 데이터를 잘 복원하기 위한 Loss)
- Lt-1 : Denoising Process Loss ( 학습 대상인 pθ(xt-1|xt)와 실제 분포 q(xt-1|xt,x0) 간의 차이를 최소화)

3. Diffusion models and denoising autoencoders
3.1 Forward Process (Diffusion Process)
- Foward process는 학습 대상이 아니었지만 β는 훈련 대상이었음
- DDPM에서는 β를 학습하지 않아도 fixed noise scheduling으로 충분한 isotropic gaussian을 확보할 수 있다고 주장
- istropic gaussian : 각 방향으로 같은 분산을 가지는, 즉 모든 방향으로 동일한 정도로 퍼져 있는 가우시안 분포
- 즉, LT(Regularization Loss) 무시 가능
3.2 Reverse Process
- Reconstruction Loss
- 전체 스텝 중 한번만 계산되기 때문에 비중이 매우 작음
- 상수 취급 가능
- Denoising Process Loss
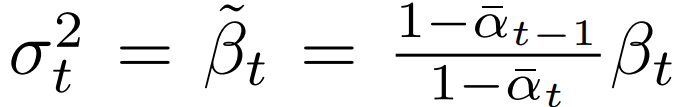
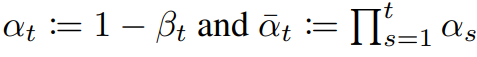

- Lt-1 (Denoising Process Loss)을 mean function 추정 관점에서 재구성


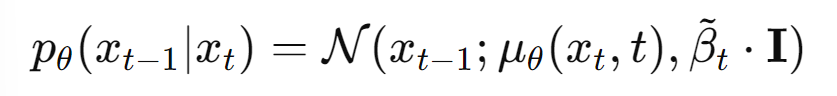
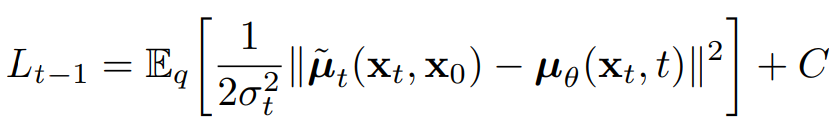
- 학습 효울성을 위해 μθ(xt, t)를 reparameterizing 함
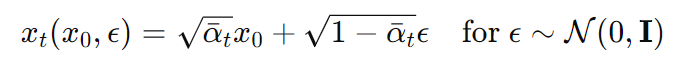
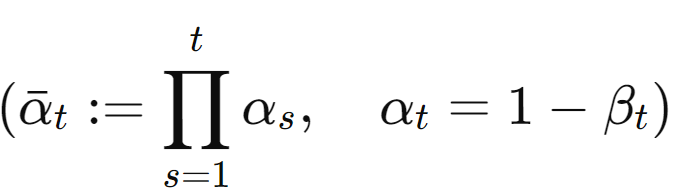
* 아래 식으로부터 도출됨
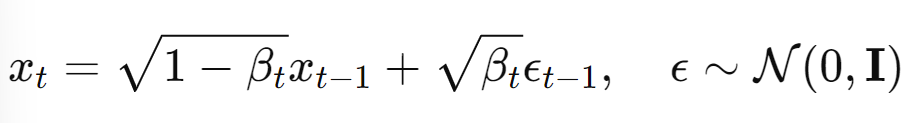
- 위에서 정의한 xt를 새롭게 재구성한 Lt-1에 대입

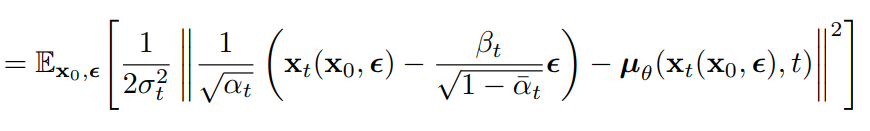
- μθ가 예측해야되는 건 noise ε뿐 (μ를 예측하려먼 데이터의 모든 복잡한 패턴을 학습해야함)
- 따라서 noise ε을 예측하여 xt에서 빼주는 방식 사용
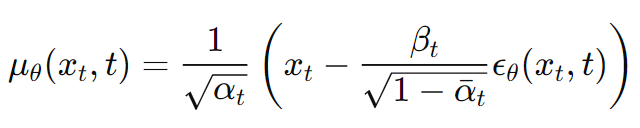
- 재구성한 μθ를 Lt-1에 대입
- ε에 대한 일종의 MSE와 같은 형태로 Loss가 변환됨
- 이처럼 각 시점의 다양한 scale의 gaussian noise를 예측하여 denoising하는 것이 DDPM의 지향점

3.4 Simplified training objective
- 새롭게 정의된 DDPM Loss (가중치항 제거)
- 이전 가중치항은 t가 작을수록 큰 값을 가짐
- 따라서 작은 t (noise가 거의 없는 상태)에서 데이터를 잘 복원하도록 많은 비중을 두었음
- 가중치항을 제거하여 큰 t에서도 학습이 잘 진행되도록 함
- 이를 통해 모델이 더 어려운 noise 제거 작업을 더 잘 학습하게 되어, 전체적인 성능 향상을 이끌어 냄

- Diffusion Loss와 비교하여 DDPM에서는 Loss가 매우 간단한 식으로 정의
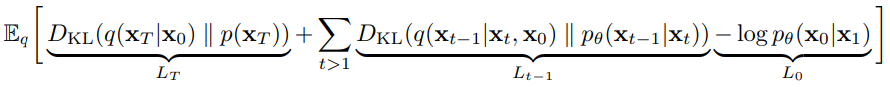
4. Experiments
4.1 Sample quality
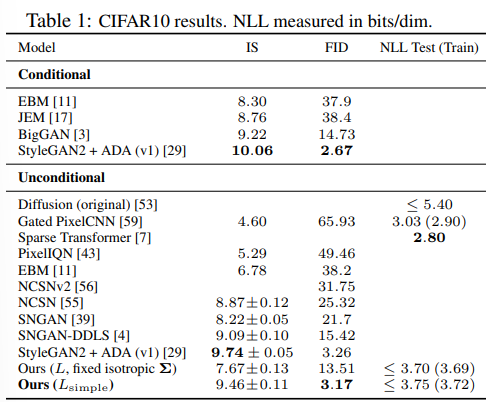
- CIFAR10에서의 평가
- Inception Score (IS) : 생성된 이미지의 품질과 다양성을 평가하는 지표
- FID Score : 생성된 이미지와 실제 이미지의 특성 분포 간의 거리 계산 (유사성 평가)
- Negative Log Liklihood (NLL) : 모델이 데이터를 얼마나 잘 설명하는지 평가하는 지표
- Unconditional 모델 : 입력으로 아무런 추가 정보를 주지 않고, 데이터만을 기반으로 이미지 생성
- Uncondtional 모델로서 다른 모델들보다 FID score에서 가장 좋은 성능을 보임
- 단순화된 loss function을 사용하면 복잡한 loss function을 사용하는 것보다 NLL이 높지만, FID에서 월등히 앞섬
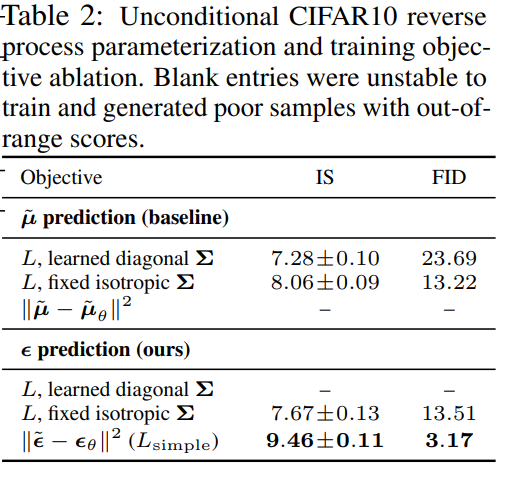
4.2 Reverse process parameterization and training objective ablation
- mean function 예측보다 ε을 예측하는 것이 성능이 더 좋음
- 특히 ε 예측에 있어 단순화된 Loss 사용 시 성능이 월등히 좋아짐
- '-' : 성능 매우 악화
- (왼쪽) CelebA-HQ 데이터셋을 사용해 256 × 256 픽셀 크기로 생성된 얼굴 이미지 샘플들
- (오른쪽) CIFAR-10 데이터셋을 사용해 32 × 32 픽셀 크기로 생성된 다양한 이미지 샘플들

5. Conclusion
- 본 논문에서는 diffusion model에서 발전된 DDPM 모델 제안
- 기존 Diffusion Loss에서 Regularization Loss와 Reconstruction Loss를 제거하고, Denoising Process Loss를 재구성
- 각 시점의 다양한 scale의 gaussian noise를 예측하는 Loss로 단순화시키면서 성능을 향상시킴
6. Reference
https://kyujinpy.tistory.com/95
https://happy-jihye.github.io/diffusion/diffusion-1/
https://www.youtube.com/watch?v=_JQSMhqXw-4
'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] Faster-RCNN 논문 리뷰 (1) | 2025.01.21 |
|---|---|
| [X:AI] MobileNet 논문 리뷰 (0) | 2025.01.12 |
| [X:AI] BYOL 논문 리뷰 (1) | 2024.08.05 |
| [X:AI] NeRF 논문 리뷰 (0) | 2024.07.28 |
| [X:AI] VAE 논문 리뷰 (0) | 2024.07.26 |



