NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
논문 원본 : https://arxiv.org/abs/2003.08934
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org

1. Abstract & Introduction
- 본 연구에서는 캡처된 이미지 세트의 렌더링 오류를 최소화하기 위해 연속적인 5D 장면 표현의 매개변수를 직접 최적화하여 오랜 문제였던 뷰 합성 문제를 새로운 방식으로 다룸
랜더링 과정
- 포인트 샘플링 : 카메라의 시점에서 광선이 장면을 지나가면서 여러 3D 지점을 샘플링
- 색상과 밀도 예측 : 샘플링한 지점들과 시점 방향을 신경망에 입력으로 넣어 각 지점의 색과 밀도 예측
- 이미지 합성 : 예측한 색상과 밀도를 사용하여 2D 이미지를 만듦
전반적인 Pipeline

3. Neural Radiance Field Scene Representation
- 연속적인 장면을 5D 벡터 값 함수로 표현
- 함수의 입력은 3D 위치 X = (x,y,z)와 2D 시점 방향 (θ, φ)
- 실제로 방향을 3D Cartesian 단위 벡터 d로 표현
- 각 입력 5D 좌표에서 색상 (r,g,b)와 밀도 σ 매핑 (MLP 사용)
- 밀도 σ의 경우 물체가 그 위치에 존재하는지에 대한 값이므로 물체를 바라보는 각도와 전혀 관계가 없으므로 위치 x의 함수로만 예측
- RGB 색상 c는 물체를 바라보는 각도에 따라 값이 변하므로 위치와 시점 방향의 함수로 예측
- 이를 위해 MLP FΘ는 먼저 입력 3D 좌표 x를 8개의 FC layer (ReLU, layer 당 256개의 채널)로 처리하고, σ와 256차원의 특징 벡터를 출력
- 그런 다음 이 특징 벡터를 카메라 광선의 시점 방향과 결합하여 하나의 추가 FC layer (ReLU, layer 당 128개의 채널)에 전달하여 시점에 따라 달라지는 RGB 색상 c 출력
- 아래 그림은 신경망이 시점에 따라 색상을 어떻게 출력하는지 보여줌
- (a)와 (b)에서는 배의 측면과 물 표면에 있는 두 고정 지점을 두 개의 다른 카메라 위치에서 본 모습

- 시점에 따른 색상 변화를 고려하고 positional encoding을 사용하는 것이 신경망이 더 현실적이고 세밀한 이미지 생성

4. Volume Rendering with Radiance Fields
가상 카메라 중심으로부터 객체를 향해 Ray를 쏨
- r(t) = o + td
- o (origin) = 카메라가 있는 곳, d = 방향
- 물체가 있을법한 범위를 정해두고 ray 위에 여러 포인트들을 샘플링
- (a)에서 ray 위의 검은색 점들
- 가장 가까운 point를 near, 가장 먼 point를 far

최종 컬러값 계산 수식 (적분 사용)
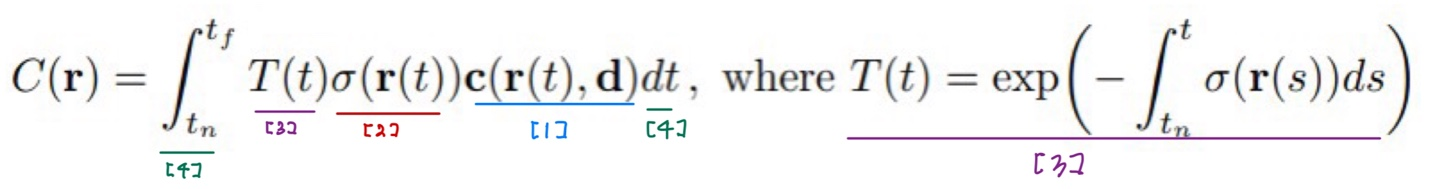
[1]
- MLP가 3D 위치 좌표와 2D 시점 방향(카메라 방향)을 받아 샘플링된 점들의 RGB 값 예측
[2]
- 밀도(density) 예측
- 색깔이 없는 점(즉, 밀도가 없는 곳)은 적분에 참여 X
[3]
- 앞에 가려진 부분의 density가 클수록, 해당 점 weight 값이 작아짐
- ray가 첫 번째로 만나는 객체의 color에 더 많은 가중치를 두기 위함
[4]
- 하지만 continuous한 적분식을 코드에서 사용할 수 있도록 discrete하게 바꿔야 함
추정 과정
[1] Sampling
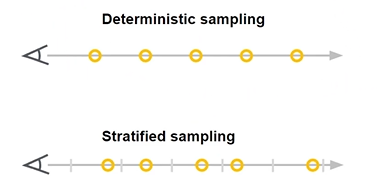
Deterministic (사용 X)
- 일정한 bin을 나누고 균등하게 sample 포인트 생성
- 하지만 매 iteration마다 같은 sample point만 학습
- 이는 rendering 해상도에 영항을 미침
Stratified (사용 O)
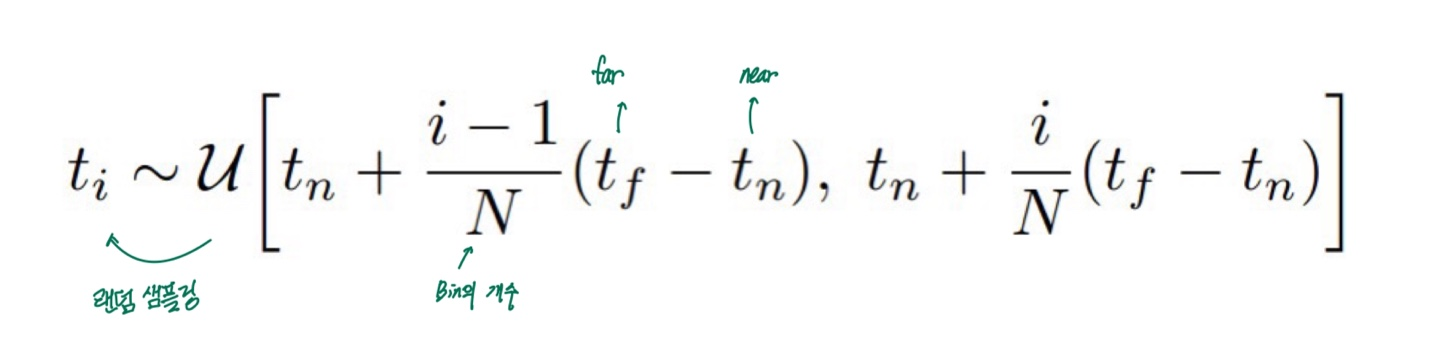
- 이전처럼 각 bin은 균등하게 나눔
- 하지만 각 bin 안에서 랜덤하게 sampling
[2] sample point를 통해 discrete하게 C(r) 추정

5. Optimizing a Neural Radiance Field
5.1 Positional encoding
- Deep Network는 lower frequency로 편향되어 학습하는 경향 존재
- 입력 좌표를 더 높은 차원의 공간을으로 변환하여 모델이 high frequency 영역까지 표현할 수 있도록 함
- ex) lower frequency : 큰 색상 블록, hig frequency : 세밀한 디테일, 날카로운 경계선
- 본 논문에서는 X(x,y,z)에 대해 L = 10, d(3D)에 대해 L = 4를 적용하여 변환
- X의 세 좌표값과 d는 모두 [-1,1] 범위로 정규화됨
- ex) L=10이면 하나의 input(ex. y)에 대해 sin, cos 0부터 9까지 20개 데이터 생성
- 즉, X는 60개 데이터 생성, d는 24개 데이터 생성

5.2 Hierarchical volume sampling & 5.3 Implementation details
- 본 연구에서는 2개의 네트워크 사용 (coarse & fine network)
- coarse sampling(Stratified) 이후 fine sampling을 통해 density가 높은 곳(즉, 객체가 있는 곳)에서 sampling을 추가 수행

Loss Fucntion
- coarse model 출력값과 실제값 사이 loss + fine model 출력값과 실제값 사이 loss
- loss는 L2 loss function을 통해 구함

6. Results
- 전반적으로 모든 데이터 셋에서 좋은 성능을 보임

Ablation studies
- Position Encoding과 View Direction을 모두 사용했을 때 가장 좋은 성능을 보임

7. Conclusion
- 본 연구는 객체와 장면을 연속 함수로 표현하기 위해 MLP를 사용하는 이전 연구의 문제점을 직접적으로 해결
- 장면을 5D neural radiance fields로 표현하는 것이 기존 방법보다 더 나은 렌더링을 생성함을 입증
- 계층적 샘플링 전략을 통해 렌더링 효율성을 높였지만, neural radiance fields의 최적화와 렌더링 효율성을 개선할 여지는 여전히 많음
8. Reference
https://mvje.tistory.com/158
https://nuggy875.tistory.com/168
https://www.youtube.com/watch?v=dyGCqLLBz50
https://www.youtube.com/watch?v=QLYDYvjRmsI
'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] DDPM 논문 리뷰 (1) | 2024.08.11 |
|---|---|
| [X:AI] BYOL 논문 리뷰 (0) | 2024.08.05 |
| [X:AI] VAE 논문 리뷰 (0) | 2024.07.26 |
| [X:AI] Detr 논문 리뷰 (1) | 2024.07.23 |
| [X:AI] MOFA-Video 논문 리뷰 (0) | 2024.07.20 |



