논문 원본 : https://arxiv.org/abs/1704.04861
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce tw
arxiv.org
Abstract
- MobileNet은 스마트폰이나 IoT 기기처럼 계산 자원이 제한된 환경에서 잘 작동하도록 설계된 딥러닝 모델
- MobileNet은 Depthwise Separable Convolution을 활용하여 경량의 딥러닝 네트워크 구축
- 해당 모델에서는 두 가지 간단한 global hyperparameter를 도입하여 latency (지연 시간 = 속도)과 정확도 사이의 균형을 효율적으로 조정할 수 있음
- 이를 통해 문제의 제약 조건에 따라 사용자가 적합한 크기의 모델을 선택할 수 있도록 함
1. Introduction
- CNN의 일반적인 추세는 더 높은 정확도를 얻기 위해 네트워크를 더 깊고 복잡하게 만드는 것
- 하지만 정확도를 높이는 이러한 발전이 반드시 네트워크의 크기와 속도 측면에서 효율성을 향상시키는 것은 아님
- 로봇공학, 자율주행차, 증강현실(AR)과 같은 계산 자원이 제한된 플랫폼에서 빠르게 인식 작업을 수행해야 됨
- MobileNet 두 가지 hyperparameter 설정을 통해 설계 요구에 맞춰 매우 작고 지연 시간이 낮은 모델을 쉽게 구축할 수 있도록 함
- 너비 조정 (width multiplier)
- 해상도 조정 (resolution multiplier)
2. Prior Work
- 최근 문헌에서는 작고 효율적인 신경망을 구축하는 데 대한 관심이 증가
- 이러한 연구는 크게 두 가지 접근 방식으로 나뉨
- 사전 학습된 모델을 압축하는 방법 (pruning, quantization)
- 처음부터 작은 모델을 설계하고 학습하는 방법 (SqueezeNet, MobileNet)
- + Distillation (큰 모델이 작은 모델을 가르쳐 더 효과적으로 학습)
- MobileNet은 속도와 크기를 모두 고려하여 설계되었는데, 특히 속도(지연 시간)을 최적화하면서도 네트워크를 작게 유지하는 데 초점을 맞췄음 (이전 연구에서는 속도를 고려하지 않음)
- 이 모델의 핵심은 depthwise separable convolution이라는 기술
- 이 기술은 복잡한 계산을 단순화해서 속도를 빠르게 하면서도 성능을 유지할 수 있도록 해줌
3. MobileNet Architecture
3.1 Depthwise Separable Convolution
- MobileNet은 Depthwise Separable Convolution을 기반으로 설계됨
- 이는 일반적인 Convolution 연산을 Depthwise Convolution과 1x1 Pointwise Convolution으로 분리하는 방식
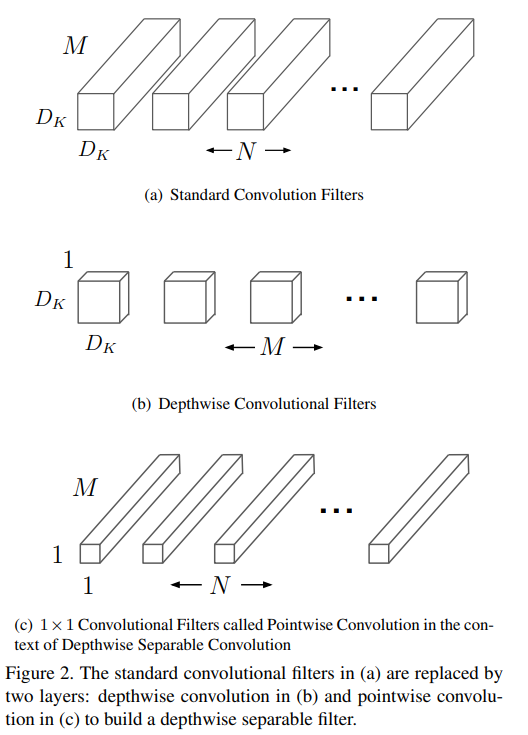
일반 Convolution과의 차이점
- 일반 Convolution : 입력 데이터를 필터링하고 결합하여 새로운 출력 데이터 생성
- Depthwise Separable Convolution
- Depthwise Convolution : 각 입력 채널에 대해 하나의 필터를 적용
- Pointwise Convolution : 1x1 convolution으로 필터링된 출력을 결합
- 이 방식은 연산량과 모델 크기를 크게 줄여주며, 정확도 손실을 최소화
수학적 설명
- 일반적인 합성곱 연산은 다음과 같음
- 입력 feature map F
- 크기 : DF x DF x M
- DF : 입력 feature map의 너비와 높이 (정사각형 가정)
- M : 입력 채널 수
- 출력 feature map G
- 크기 : DF x DF x N
- N : 출력 채널 수
- 커널(필터) 크기
- DK x DK (정사각형 가정)
- ex) 3 x 3 filter
- 총 연산량
- 연산량 = DK x DK x M x N x DF x DF
- 입력 feature map F
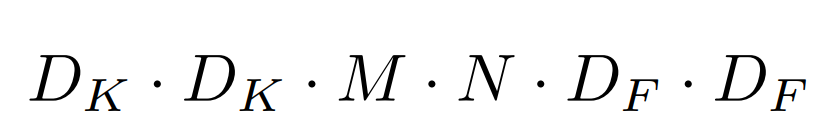
- Depthwise Separable Convolution은 위 연산을 두 단계로 나누어 수행
- Depthwise Convolution
- 각 채널에 하나의 필터를 적용
- 연산량 : DK x DK x M x DF x DF
- Pointwsie Convolution
- 1x1 필터로 채널 간 결합 수행
- 연산량 : M x N x DF x DF
- 총 연산량
- DK x DK x M x DF x DF + M X N X DF X DF
- Depthwise Convolution
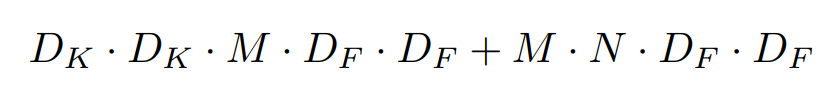
- 연산량 비교
- 출력 채널 N이 많아질수록 1/N은 작아짐
- 커널 크기 Dk가 클루속 1/ D2K는 작아짐
- ex) N = 32, DK = 3
- 비율 ≈ 0.03125 + 0.111 = 0.142
- 이는 Depthwise Separable Convolution의 연산량이 일반 Convolution의 약 14.2%에 불과하다는 뜻
- MobileNet은 DK = 3 (3x3 filter) 사용
- 은 출력 채널 수에 따라 다르지만, 일반적으로 8~9배 적은 연산량으로 처리할 수 있음
- 이렇게 하면 모델이 훨씬 가볍고 빨라지며, 모바일 기기와 같이 자원이 제한된 환경에서도 딥러닝 모델을 사용할 수 있음 (성능도 유지 -> 필터링과 채널 결합은 일반 Convolution과 방법론만 다를 뿐이지 동일하게 수행)
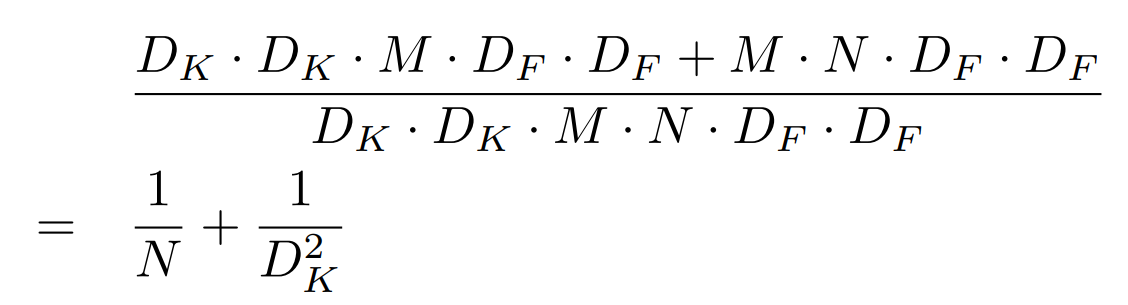
3.2 Network Structure and Training
- MobileNet 첫 번째 레이어는 일반 Convolution을 사용
- 모든 레이어는 Batch Norm과 ReLU 사용
- 최종 FC Layer에는 활성화 함수가 없으며, Softmax를 통해 분류 작업 수행
- 네트워크에서 다운샘플링은 다음과 같이 처리
- Stride를 사용하는 Depthwise Convolution Layer
- 첫 번째 일반 Convolution Layer
- 최종적으로 Avearge Pooling을 통해 공간 해상도를 1로 줄인 후 FC Layer로 연결
- MobileNet은 총 28개의 레이로 구성

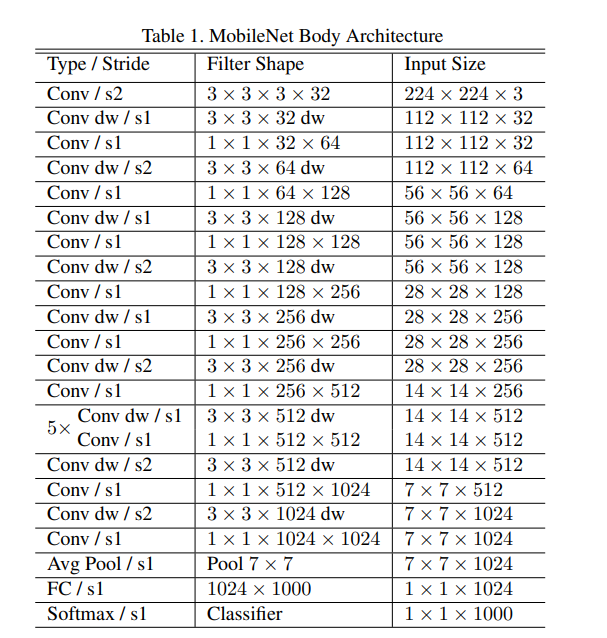
- MobileNet은 1×1 포인트 합성곱에 대부분의 연산을 집중
- 장점: 1×1 합성곱은 고도로 최적화된 행렬 연산(GEMM, General Matrix Multiply)을 사용하여 계산이 빠름
- 추가 작업 최소화: 1×1 합성곱은 메모리 재정렬(im2col)이 필요 없기 때문에, 기존의 3×3 합성곱보다 효율적
- MobileNet의 계산 시간의 95%가 1×1 합성곱에서 소비되며, 모델 파라미터의 75%도 1×1 합성곱에 집중되어 있음
- 나머지 파라미터는 주로 FC Layer에 있음
3.3 Width Multiplier : Thinner Models
- 기본 MobileNet 아키텍처는 이미 작고 지연이 적지만, 특정 사용 사례나 애플리케이션에서는 더 작은 모델 필요
- 이를 위해 MobileNet에서는 너비 계수(Width Multiplier) α라는 간단한 매개변수를 도입
- 이 α는 네트워크의 모든 레이어에서 입력 채널과 출력 채널의 수를 균일하게 줄이는 역할을 함
- α: 0<α≤10의 값을 가지며, 일반적인 값은 1, 0.75, 0.5, 0.25
- : 기본 MobileNet 구조 (Baseline Model)
- : 축소된 MobileNet 구조 (Reduced MobileNet)
- 입력 채널 수와 출력 채널 수는 각각 다음과 같이 조정
- 계산 비용
- 효과
- 너비 계수 는 연산량과 파라미터 수를 대략 비율로 줄임
- 를 조정해 모델 크기, 속도, 정확도 간의 균형을 조정할 수 있음
- 단, 너비 계수를 변경하면 새롭게 모델을 학습시켜야 함
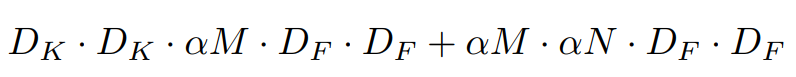
3.4 Resolution Multiplier : Reduced Representation
- 두 번째로 연산 비용을 줄이는 방법은 해상도 계수 (Resolution Multiplier) ρ 사용
- 이는 입력 이미지의 해상도를 줄여 네트워크 내부의 모든 레이어의 representation 크기를 줄이는 역할을 함
- ρ : 의 값을 가짐
- 일반적인 입력 해상도:
- : 기본 MobileNet 구조
- : 축소된 MobileNet 구조
- 계산 비용
- 효과:
- 해상도 계수 는 연산 비용을 대략 비율로 줄임
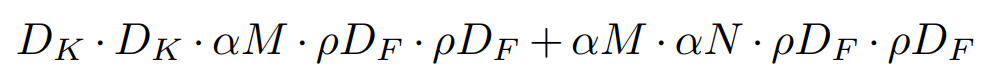
4. Experiments
4.1 Model Choices
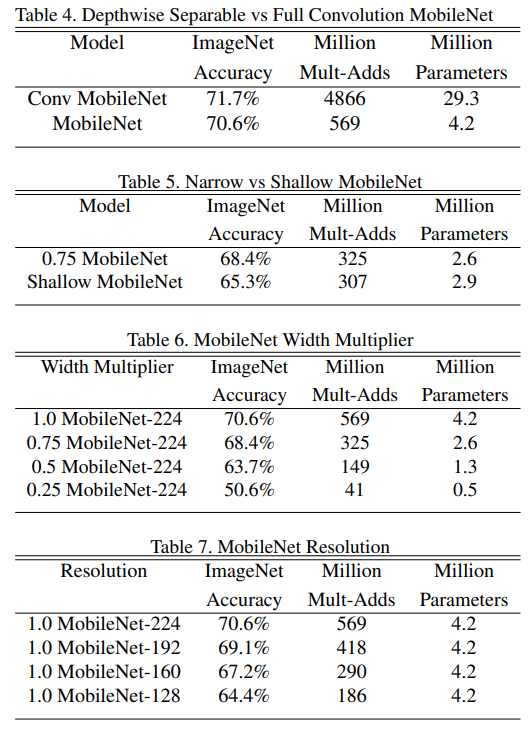
- Depthwise Separable Convolution의 효과
- 기존의 Full Convolution과 비교했을 때, 정확도는 1%만 감소했지만, 연산량(Mult-Adds)과 파라미터는 크게 감소
- 얇은 모델(Width Multiplier) vs 얕은 모델(Less Layers):
- 얇은 모델이 얕은 모델보다 정확도가 3% 더 높음
- 얕은 모델을 구현하기 위해 1 크기의 5개 레이어를 제거
4.2 Model Shrinking Hyperparameters
- Width Multiplier ()
- 가 감소할수록 연산량과 파라미터 수가 줄지만, 정확도는 점진적으로 감소
- 에서 모델 성능 급락
- Resolution Multiplier ()
- 입력 이미지 해상도를 줄일수록 연산량 감소와 함께 정확도도 부드럽게 감소
- 해상도 에서 실험.
- 결합 효과
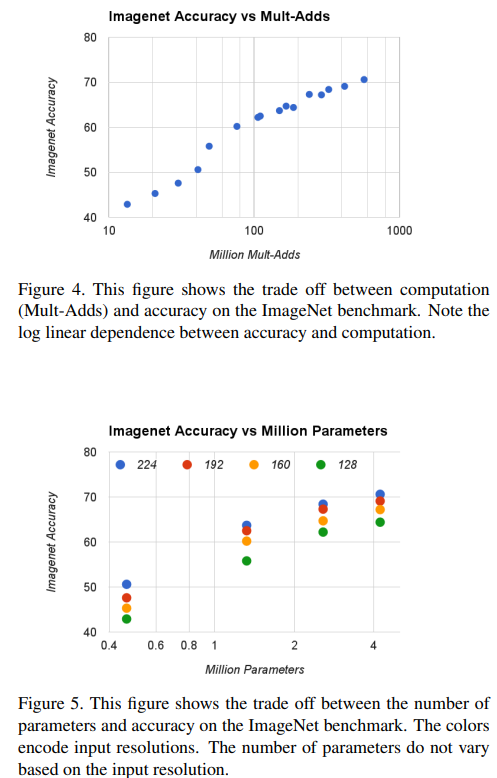
- 와 를 조합한 16개의 모델에서 정확도와 연산량, 파라미터 간의 로그 선형 관계 확인
- 와 낮은 해상도 조합에서 정확도 급락
4.3 Fine Grained Recognition
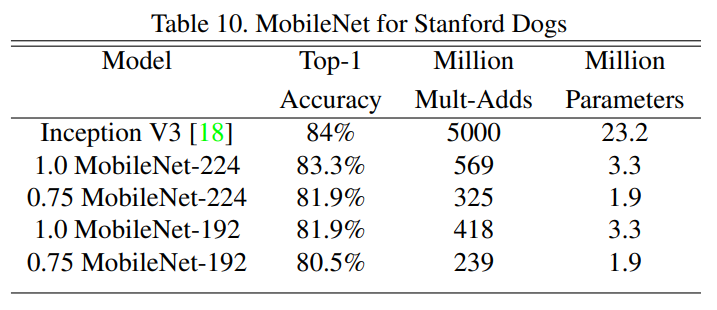
- Stanford Dogs Dataset
- MobileNet을 사용한 세밀한 개 품종 분류에서 기존 모델의 성능에 근접하며, 연산량과 모델 크기를 대폭 감소
4.4 Large Scale Geolocalization
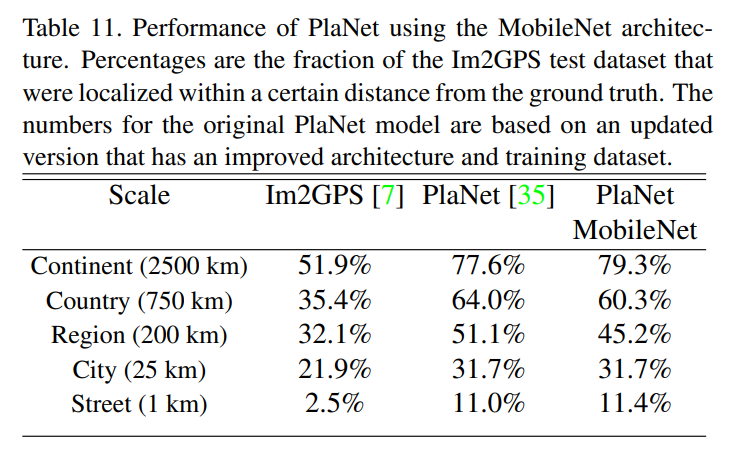
- PlaNet 재학습
- MobileNet 기반 PlaNet은 원래 Inception V3 기반 모델보다 4배 작은 파라미터(13M)와 10배 적은 연산량(0.58B Mult-Adds)을 사용
- 성능은 약간 낮지만 여전히 뛰어난 결과를 유지하며, 기존의 Im2GPS를 능가
4.5 Face Attributes
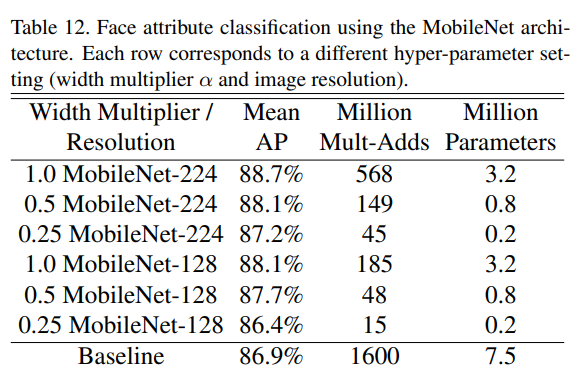
- Distillation 기법 활용
- MobileNet으로 기존 75M 파라미터와 1600M Mult-Adds를 가진 얼굴 속성 분류 모델을 경량화
- MobileNet 기반 모델은 동일한 성능(mean Average Precision)을 유지하면서 연산량을 1%로 감소
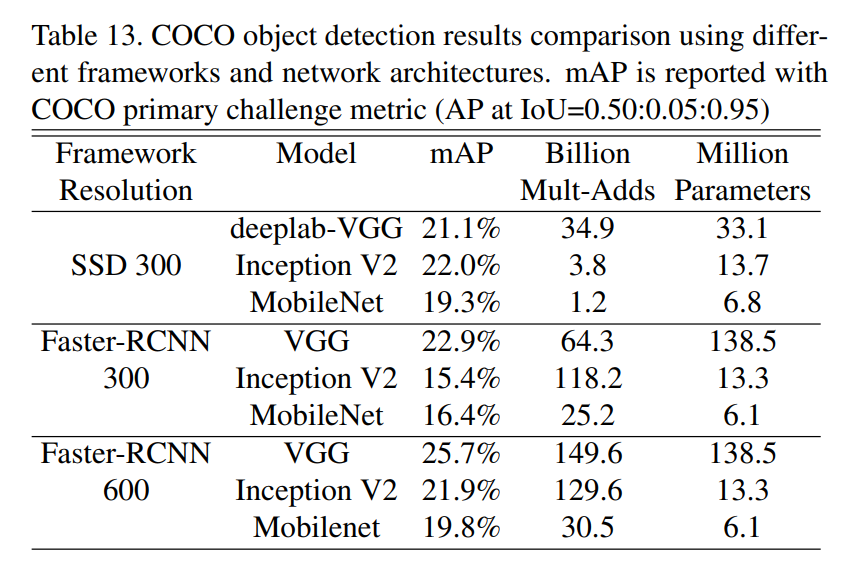
4.6 Object Detection
- COCO 데이터셋에서 Faster-RCNN 및 SSD 프레임워크로 MobileNet 테스트
- Faster-RCNN: VGG, Inception V2와 비교해 유사한 성능을 유지하면서 계산 복잡도와 모델 크기를 크게 줄임
- SSD: 300×300 해상도에서 효율적이며, 다른 모델 대비 연산량 감소
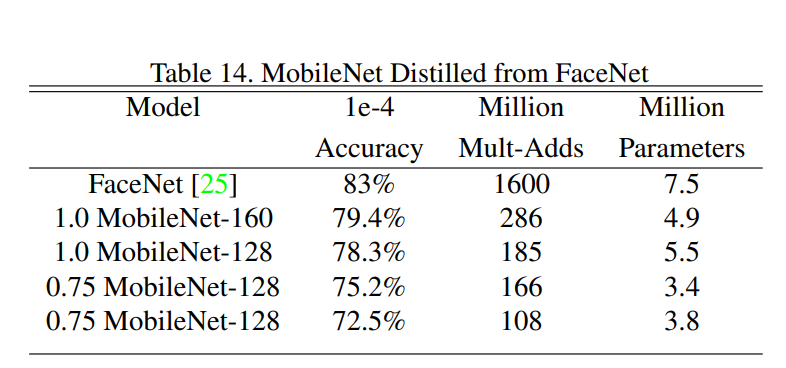
4.7 Face Embeddings
- FaceNet 모델의 경량화
- MobileNet을 FaceNet으로 학습시키는 Distillation 기법 사용
- 매우 작은 MobileNet 모델에서도 우수한 얼굴 임베딩 성능을 보여줌
5. Conclusion
- MobileNet은 Depthwise Separable Convolution을 기반으로 설계된 새로운 모델 아키텍처로, 연산량과 모델 크기를 크게 줄이는 데 초점
- Width Multiplier와 Resolution Multiplier를 사용하여 더 작고 빠른 MobileNet을 구현 (합리적인 수준에서 정확도 희생)
'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] YOLO 논문 리뷰 (0) | 2025.01.28 |
|---|---|
| [X:AI] Faster-RCNN 논문 리뷰 (1) | 2025.01.21 |
| [X:AI] DDPM 논문 리뷰 (1) | 2024.08.11 |
| [X:AI] BYOL 논문 리뷰 (0) | 2024.08.05 |
| [X:AI] NeRF 논문 리뷰 (0) | 2024.07.28 |



