논문 원본 : https://arxiv.org/abs/1506.01497
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottle
arxiv.org
1. Abstract & Introduction
- 기존 방식의 문제점
- 객체를 탐지하려면 이미지 속 관심 영역(Region)을 먼저 찾아야 함
- 기존의 영역 제안 방법(Selective Search)은 CPU에서 작동하고 속도가 느려서, 실제 객체 탐지 시스템의 병목현상이 되었음
- 새로운 방법 - RPN (Region Proposal Network)
- RPN은 딥러닝(CNN)을 이용해 영역 제안을 수행하는 새로운 방법
- 영역 제안 작업을 객체 탐지 네트워크와 통합하여 같은 컨불루션 연산을 공유
- 이로 인해 추가적인 계산 비용이 거의 들지 않으며, 이미지당 10ms 만에 영역 제안을 할 수 있음
- 핵심 아이디어 - 앵커 박스
- 기존 방법은 다양한 크기와 비율의 영역을 처리하기 위해 이미지 피라미드를 만들어야 했음(비용 증가)
- RPN은 이를 대신해 앵커 박스라는 기준점을 설정하여 영역을 예측 (미리 정의된 크기와 비율)
- 따라서 단일 스케일 이미지로도 충분히 효과적인 결과를 냄
2. Related Work
후보 영역 (Region Proposal) 추출 알고리즘
- 입력 이미지에 서 객체가 있을 법한 영역을 찾아내는 알고리즘
- sliding window, selective search, edge boxes 알고리즘 등
Sliding Window
- 물체가 존재할 수 있는 모든 크기의 영역에 대해 이미지를 모두 탐색 (box 크기 다양화)
- 탐색해야 하는 공간이 너무 크거나, 다양한 box 크기에 대해서 모두 탐색 수행 시 연산 시간이 오래 걸림

Selective search
- sliding window방식보다 검색 공간이 줄어들기 때문에 훨씬 빠른 속도로 영역 추출
- 초기 sub-segmenation 수행
- 각각의 객체가 1개의 영역에 할당될 수 있게 많은 초기 영역 생성
- 작은 영역을 반복적으로 큰 영역으로 통합
- 여려 영역으로부터 가장 비슷한 영역 두가지 선택 (컬러, 무늬, 명암 등 고려)
- 더 이상 합칠 수 없는 1개의 큰 영역이 남을 때까지 반복
- 통합된 영역을 바탕으로 후보 영역 생성

R-CNN
- 딥러닝을 활용한 객체 검출의 시초
- 객체 검출 문제에 CNN에 적용한 첫 논문
- 이미지에서 Selective Search를 수행하여 Region proposals 추출
- 추출된 후보 영역을 이미지로부터 잘라냄 (cropping)
- 고정 사이즈를 갖도록 크기 변환(wrapping)하여 CNN 투입
- CNN에서 만들어진 feature로 SVM을 통해 각 후보 영역에 대한 분류 수행
- 2000개의 후보 영역이 검출되었으면, 2000번 분류 수행
- Bounding box의 정확도를 높이기 위해 Bounding box 선형 회귀 수행


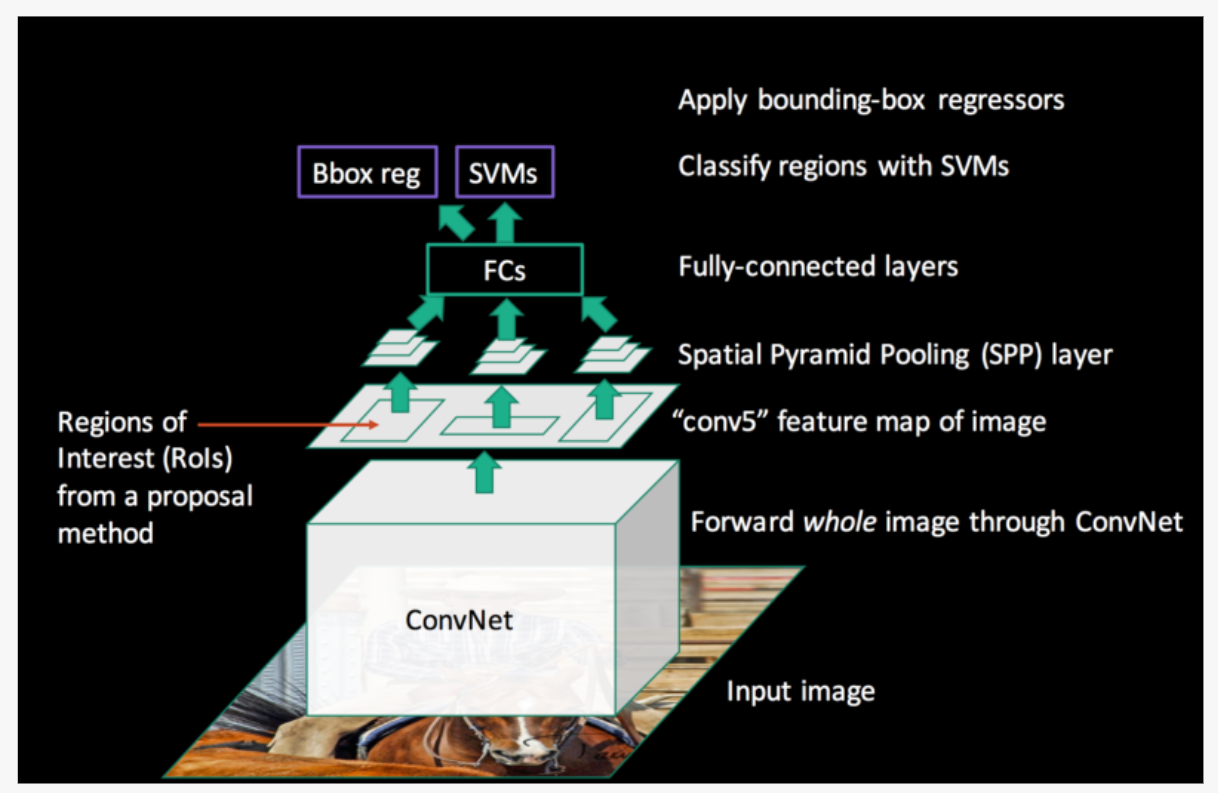
Fast R-CNN
- R-CNN의 한계점을 극복하고자 제안된 모델
- RoI(Region of Interest) pooling 사용
- CNN / 분류 / bounding box regression까지 하나의 모델에서 학습
- 분류 손실 함수(Log loss) + bounding box regression(Smooth L1) 한 번에 계산
- 전체 이미지를 CNN에 통과시켜 Feature map 추출
- Selective Search를 통해 RoI를 찾음
- RoI를 feature map 크기에 맞춰 projection 시킴
- projection시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector을 얻음 (for FC)
- Feature vector는 FC layer를 통과한 뒤, 두 branch로 나뉘어
- 하나는 softmax를 통과하여 RoI에 대해 object classification
- 다른 하나는 bounding box regressor를 통해 selective search로 찾는 box의 위치 조정

RoI pooling
- Projection 시킨 RoI를 FC layer에 투입하기 위해서는 같은 크기의 feature map 필요
- 크기가 다른 Feature map의 RoI마다 Stride를 다르게 하여 Max pooling 진행하여 크기를 맞춤
- Stride (4/2=2, 5/2=2)로 좌상단 pooling 영역을 정하고, 이로부터 max pooling 수행

3. Faster R-CNN
- Faster R-CNN은 크게 두 가지 모듈로 구성
- Region Proposal Network (RPN) : 입력 이미지를 받아 객체가 있을 법한 영역(Region) 제안
- Fast R-CNN Detector : RPN이 제안한 영역을 사용해 객체 탐지
- 이 두 모듈은 통합된 하나의 신경망으로 구성되어 있음
- RPN은 Fast R-CNN이 어디를 봐야 할지 알려주는 역할

3.1 Region Proposal Networks (RPN)
- 이미지를 넣으면, 먼저 합성곱 신경망(ZF or VGG16)을 사용해 feature map을 만듦
- Fast R-CNN과 RPN은 같은 합성곱 신경망 계층을 공유( = 같은 feature map 사용)
- 그 특징 맵 위를 작은 네트워크가 슬라이딩하며 돌아다니면서 크기의 작은 영역(window)을 관찰
- 슬라이딩 방식은 한 번에 전체 이미지를 보는 대신, 특징 맵의 일부 영역만 처리
- 이렇게 하면 연산량을 줄이고, 효율적으로 지역 제안을 생성할 수 있음
- 3x3 영역을 압축하여 저차원 벡터로 변환 (ZF는 256 차원, VGG16은 512차원 / ReLU 활성화 함수로 처리)
- 추출된 특징은 두 가지 예측 계층으로 전달 (1x1 합성곱을 통해 계산됨)
- cls (Classification)
- 2k : k는 anchor 개수 (각 anchor마다 객체일 확률과 아닐 확률 2개를 예측)
- 해당 영역에 물체가 있다면, 물체의 사각형 영역 좌표를 예측
- 예측 결과는 박스의 중심 좌표와 크기(너비와 높이)로 표현
- reg (Regression)
- 4k : k는 anchor 개수 (각 anchor마다 4개의 좌표값 예측)
- 해당 영역이 물체를 포함하고 있을 가능성을 점수로 나타냄
- cls (Classification)

3.1.1 Anchors
- 슬라이딩 윈도우 방식에서, 본 논문은 각 위치에서 여러 개의 region proposals를 동시에 예측
- 각 위치에서 생성할 수 있는 최대 proposals 수를 k로 표시
- 따라서 reg 레이어는 k개의 박스 좌표를 인코딩하는 4k개의 출력을 가지며, cls 레이어는 각 제안에 대해 객체일 확률과 아닐 확률을 나타내는 2k개의 점수를 출력
- 각 슬라이딩 윈도우 중심에서 미리 정의된 박스들(reference boxes), 즉 앵커를 배치
- 앵커는 다양한 크기(Scale)와 가로 세로 비율(Aspect Ratio)을 가짐
- 기본적으로 3가지 크기와 3가지 비율을 조합하여, 한 위치에서 총 9개의 앵커를 만듦
Translation-Invariant Anchors
- 객체가 이미지에서 위치를 옮기더라도(예: 위에서 아래로 이동) 앵커 박스와 예측 방식은 동일하게 적용
- 즉, 이미지에서 특정 위치에 객체가 있으면 그 위치에서 앵커가 해당 객체를 탐지하고, 객체가 이동하면 새로운 위치의 앵커가 탐지
- 이렇게 하면 이미지의 이동이나 크기 변화에도 일관된 방식으로 객체를 탐지할 수 있음
Multi-Scale Anchors
- 이미지/특징 피라미드 방식
- 이미지를 여러 크기로 리사이즈하고, 각 크기에서 특징 맵을 계산
- 이렇게 하면 다양한 크기의 객체를 탐지할 수 있지만, 매우 시간이 오래 걸림
- 다중 스케일의 슬라이딩 윈도우
- 객체 크기에 맞춘 다양한 크기와 비율의 필터를 학습해야 함
- 필터 크기가 많아질수록 모델이 복잡해지고 학습 비용이 증가
- RPN은 단일 크기의 특징 맵과 단일 크기의 필터만 사용
- 대신, 각 위치에서 3개의 크기와 3개의 종횡비로 구성된 앵커 박스를 설정
- 이렇게 하면 추가적인 이미지 리사이즈나 필터 훈련 없이, 다양한 크기의 객체를 탐지할 수 있고 계산 효율성이 크게 향상

3.1.2 Loss Function
- RPN(Region Proposal Network)을 훈련하기 위해, 각 앵커(anchor)에 이진 클래스 레이블(객체 또는 비객체)을 할당
- 양성 레이블(positive label)은 다음 조건을 만족하는 앵커에 부여
- IoU(Intersection-over-Union)가 가장 높은 앵커(ground-truth 박스와의 겹치는 비율)
- IoU > 0.7인 앵커
- 한 ground-truth 박스는 여러 앵커에 양성 레이블을 할당할 수 있음
- 첫 번째 조건은 드물게 두 번째 조건을 만족하는 앵커가 없을 때 사용
- 음성 레이블(negative label)은 다음 조건을 만족하는 앵커에 부여
- 모든 ground-truth 박스와의 IoU가 0.3보다 낮은 앵커
- 중립 상태
- 양성도 아니고 음성도 아닌 앵커는 훈련 손실에 기여하지 않음
RPN Loss Function
- :
- 분류 손실로, 앵커 가 객체인지 아닌지에 대한 확률 를 예측
- Ground-truth 레이블 는 객체일 경우 1, 그렇지 않으면 0
- 로그 손실을 사용(이진 분류에서 자주 사용)
-
- 회귀 손실로, 앵커 박스 가 ground-truth 박스 와 얼마나 잘 맞는지 계산
- Smooth L1 손실을 사용
- 작은 오차 구간에서는 MSE처럼 동작하여 작은 차이에 대해 더 정밀한 학습
- 오차가 클 때는 를 사용하여 평균 절대 오차(MAE)처럼 동작
- 큰 오차에서 손실이 선형으로 증가하므로, 큰 오차의 영향을 줄이고 안정적인 학습을 가능
- 이 손실은 양성 앵커()에 대해서만 활성화

- 정규화 및 가중치
- 분류 손실()은 미니배치 크기 으로 정규화
- 회귀 손실()은 앵커 위치 수 로 정규화
- 두 손실의 균형을 맞추기 위해 가중치 λ = 10을 사용
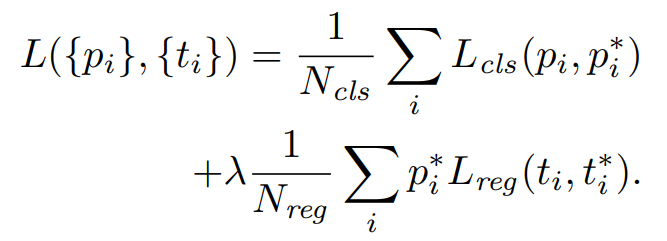
- bounding box regression
- 중심 좌표 조정 (tx, )
- 중심 좌표 를 앵커 박스 중심 에서 얼마나 이동해야 하는지를 상대적으로 계산
- 너비와 높이 조정 ():
- 너비 와 높이 를 앵커 에 맞춰 얼마나 조정해야 하는지를 로그 스케일로 계산
- 중심 좌표 조정 (tx, )
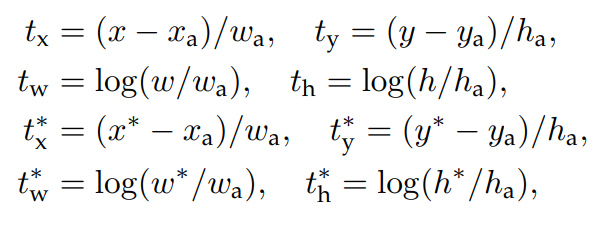
3.2 Sharing Features for RPN and Fast R-CNN
4-Step Alternating Training
- 1단계
- ImageNet으로 사전 학습된 CNN 모델을 기반으로 RPN을 훈련.
- region proposal을 생성하는 데 최적화
- 2단계
- 1단계에서 region proposals을 사용해 Fast R-CNN 훈련
- 이 단계에서 RPN과 Fast R-CNN은 합성곱 계층을 공유하지 않음
- 3단계
- 2단계에서 훈련된 Fast R-CNN 모델을 사용해 RPN 재훈련
- 이때, 공유된 합성곱 계층은 고정하고, RPN 고유 계층만 미세 조정(fine-tune)
- 4단계
- 3단계에서 고정된 합성곱 계층을 유지하며, Fast R-CNN 고유 계층을 다시 미세 조정
- 이 과정 후 RPN과 Fast R-CNN은 같은 합성곱 계층을 공유하며 하나의 통합된 네트워크를 형성
3.3 Implementation Details
- 3가지 크기(128², 256², 512²)와 3가지 종횡비(1:1, 1:2, 2:1)로 구성된 개의 앵커 박스를 사용
- 앵커가 이미지 경계를 넘어가는 경우, 훈련 중에는 해당 앵커를 무시(손실에 포함하지 않음)
- 훈련: 경계를 넘는 앵커 제거 → 약 6000개의 앵커 사용
- 테스트: 경계를 넘는 proposal box를 생성하지만, 이미지 경계에 맞게 잘라냄
- RPN에서 생성된 proposal 중 겹치는 박스를 제거하기 위해 NMS(Non-Maximum Suppression) 적용
- IoU(Intersection over Union) 임계값을 0.7로 설정
- 0.7 이상 겹치는 제안 중 가장 높은 점수를 가진 하나만 남김
- NMS 이후 약 2000개의 제안을 남기고, 이를 Fast R-CNN 훈련에 사용
4. Evaluation
4.1 Experiments on PASCAL VOC
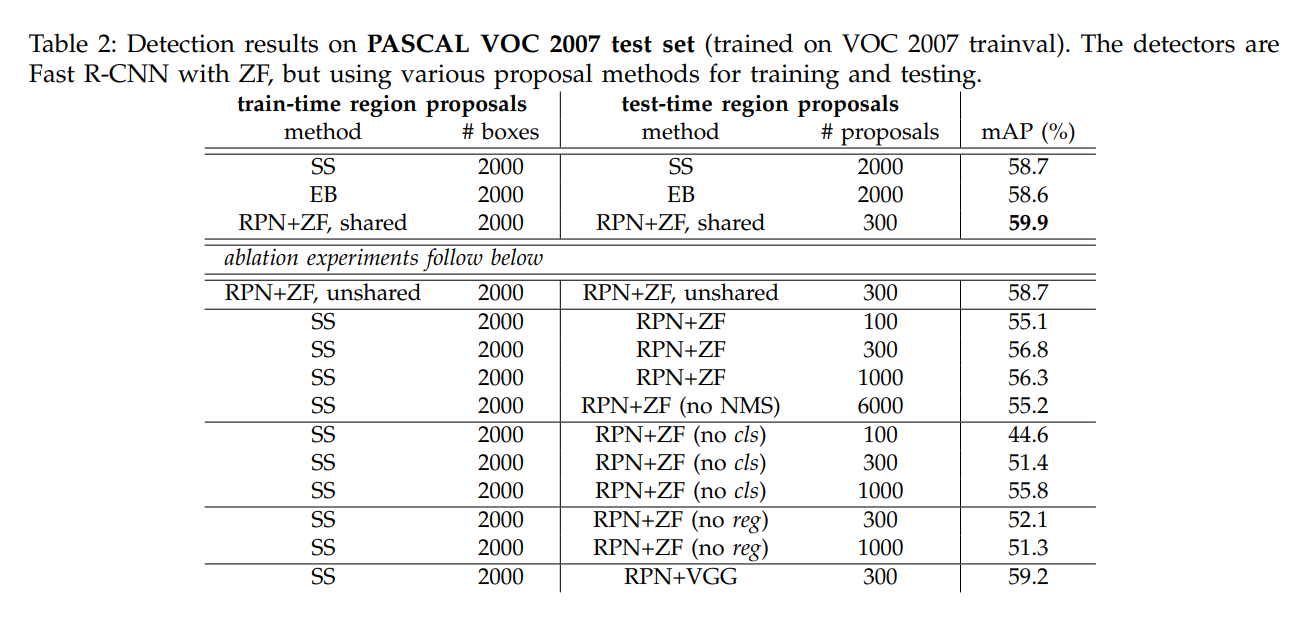
- RPN vs 기존 방법
- RPN + Fast R-CNN (ZF): mAP 59.9%
- 기존 방법
- Selective Search(SS): mAP 58.7%
- EdgeBoxes(EB): mAP 58.6%
- RPN은 더 적은 proposal(300개)으로 더 높은 정확도를 달성
- RPN proposal 수와 정확도 관계
- RPN 제안을 300개로 줄여도 높은 정확도 유지
- NMS 적용 후 300개의 제안: mAP 59.9%
- NMS 미적용 시 6000개 제안: mAP 55.2%
- cls와 reg의 역할
- cls 레이어 제거: mAP 크게 감소 (44.6%)
- reg 레이어 제거: mAP 감소 (52.1%)
- cls와 reg 모두 정확도에 중요한 역할
- 모델 비교 (VGG vs ZF)
- VGG-16 모델 사용 시 mAP 69.9% (ZF보다 약 10% 향상)
4.2 Experiments on MS COCO
- Faster R-CNN 성능
- mAP@[.5, .95]: 21.5% (train set 사용) → 21.9% (trainval set 사용)
- mAP@0.5: 42.7%
- 기존 Fast R-CNN보다 약 2.8% 높은 정확도
- ResNet-101 사용 시
- VGG-16 대비 정확도 대폭 향상
- mAP@[.5, .95]: 27.2% (VGG-16: 21.2%)
- mAP@0.5: 48.4% (VGG-16: 41.5%)
- VGG-16 대비 정확도 대폭 향상
- COCO에서 추가 데이터 사용 효과
- COCO에서 학습 후 PASCAL VOC에 적용 시 mAP 76.1% (VOC 데이터 미사용)
- COCO + VOC 데이터로 학습 시 mAP 78.8%

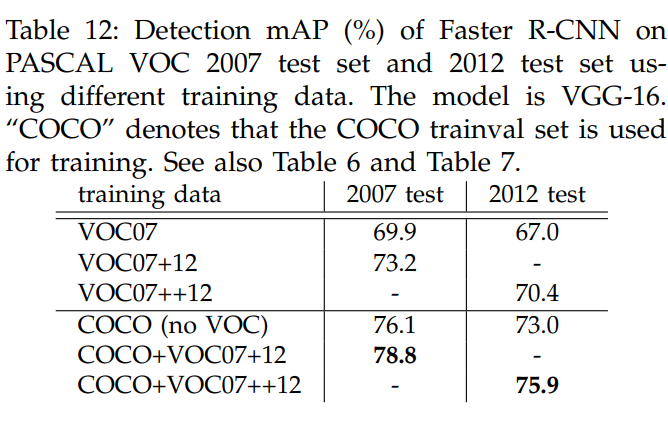
4.3 From MS COCO to PASCAL VOC
- 대규모 데이터 전이 학습 효과
- COCO 데이터로 사전 학습한 Faster R-CNN을 PASCAL VOC에서 미세 조정(fine-tuning)하면 5.6% mAP 상승 (73.2% → 78.8%)
5. Conclusion
- RPN(Region Proposal Network)의 장점
- RPN을 통해 효율적이고 정확한 객체 제안(region proposal)이 가능
- 기존의 제안 방식(Selective Search, EdgeBoxes) 대비 거의 추가 비용 없이 제안 생성
- 통합 네트워크
- RPN과 객체 탐지 네트워크(Fast R-CNN)가 합성곱 계층을 공유하여 효율성을 극대화
- 이로 인해 Faster R-CNN은 단일 딥러닝 기반 객체 탐지 시스템으로 동작
- 실시간 속도
- 통합된 네트워크 덕분에 실시간에 가까운 속도로 동작 가능
- 성능 향상
- 학습된 RPN은 제안 박스 품질을 향상시켜, 객체 탐지 정확도도 높임
'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] RetinaNet 논문 리뷰 (1) | 2025.02.03 |
|---|---|
| [X:AI] YOLO 논문 리뷰 (1) | 2025.01.28 |
| [X:AI] MobileNet 논문 리뷰 (2) | 2025.01.12 |
| [X:AI] DDPM 논문 리뷰 (1) | 2024.08.11 |
| [X:AI] BYOL 논문 리뷰 (2) | 2024.08.05 |



