MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model
논문 원본 : https://arxiv.org/abs/2405.20222
MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model
We present MOFA-Video, an advanced controllable image animation method that generates video from the given image using various additional controllable signals (such as human landmarks reference, manual trajectories, and another even provided video) or thei
arxiv.org
발표 영상 : https://www.youtube.com/watch?v=wICGrNw55Ec
발표 자료
1. Abstract & Introduction
기존 Image2Video 방법론의 한계
특정 도메인 최적화 (일반적인 이미지에 잘 적용 X)
- SadTalker는 오디오와 주어진 얼굴(제어 신호)을 통해 인간 얼굴 애니메이션 생성
- Text2Cinemagraph : 텍스트 설명(제어 신호)을 사용하여 물의 자연스러운 애니메이션 생성
새로운 접근 방식
- MOFA-Video : Stable Video Diffusion(기존 비디오 생성 모델,안정적이고 일관된 품질의 비디오 생성)에 다양한 제어 신호 (ex. human landmarks reference, manual trajectories, another video)를 추가하여 더 정밀하고 다양한 비디오 생성할 수 있음
MOFA-Video 개선
Multi domains control
- 여러 domain의 제어 신호를 동시에 받아들일 수 있어, 인간의 얼굴, 배경 객체, 카메라 움직임 등 모두 제어 가능
프레임 간 일관성
- Sparse Motion Hint(ex. 사람의 주요 관절이나 얼굴의 특정 지점, 사용자가 직접 지정한 경로, 다른 비디오의 움직임 데이터)을 기반으로 더 세밀한 움직임(dense motion field) 생성
- 첫 번째 프레임의 다양한 특징을 활용하여, 시간적으로 일관된 비디오 생성 (첫 번째 사진의 배경, 조명, 인물 표정 등을 파악하여 모든 프레임에서 비슷하게 유지)
=> 고품질 애니메이션 생성

2. Stable Video Diffusion (SVD)
Encoder
- 사전 학습된 auto-encoder를 통해 latent space로 압축
- latent space : 원본 이미지의 중요한 특징을 더 작은 차원으로 표현하는 공간 (쉽게 말해, 이미지를 더 간단한 형태로 압축한다고 생각하면 됨)
Diffusion Process
- 모든 픽셀이 랜덤한 값으로 채워진 noise 이미지에서 시작
- 점차 gaussian noise를 제거하면서 condition image를 반영한 latent space 표현 생성
Decoder
- 각 단계에서 noise가 제거된 latent space 표현 받아 실제 이미지로 변환
- 각 단계에서 생성된 이미지를 순차적으로 연결하여 비디오 생성
ex) Condition image : 놀란 디카프리오 사진
- 첫 번째 프레임: 디카프리오의 희미한 형태가 나타남
- 두 번째 프레임: 입이 약간 벌어짐
- 세 번째 프레임: 입이 더 크게 벌어짐
- 최종 결과: 각 프레임을 연결하여 디카프리오가 놀라는 비디오 생성

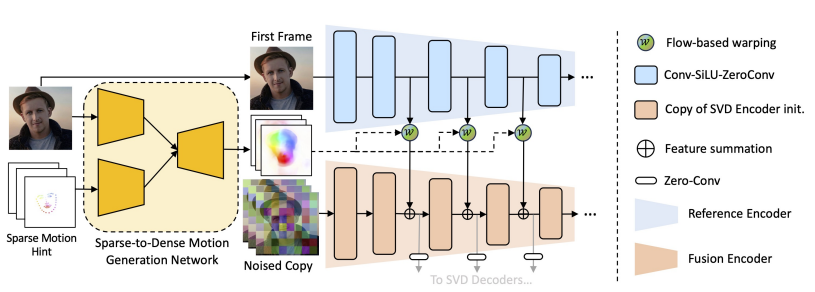
3. MOFA-Adapter
- 비디오 생성 과정에서 Sparse Motion Hint (hand-crafted trajectories, human pose 등)를 추가하여, 사전 학습된 SVD(Stable Video Diffusion)모델이 더 정밀하고 다양한 주제의 비디오를 생성하도록 도와줌
Reference Encdoer
- 여러 단계로 구성된 Conv-SiLU-ZeroConv 블록을 거쳐 첫 번째 프레임의 multi-scale features 추출
- SiLU : 활섬화 함수 중 하나로, Sigmoid와 ReLU의 특징을 결합한 형태 (비선형성 추가)
- ZeroConv : 필터 값을 0으로 초기화하여, 모델 학습을 안정적으로 시작할 수 있도록 함 (잘못된 초기화는 학습을 불안정하게 만듦)
Sparse-to-Dense Motion Generator (S2D)
- 첫 번째 프레임 이미지와 Sparse Motion Hint를 입력 받아 Dense Motion Field 생성(더 세밀한 움직임 계산)
Feature Fusion Encoder
- Dense Motion Field를 사용하여 첫 번째 프레임의 추출된 feature 변형 (Flow-based warping)
- 이미지의 중요한 정보가 유지되면서 세밀한 움직임이 반영
- 변형된 feature을 사전 학습된 SVD(Stable Video Diffusion) Encoder의 해당 level의 feature map에 추가
- 그 후 사전 학습된 SVD(Stable Video Diffusion) Decoder로 전달되어 비디오의 각 프레임을 생성
Animation via Multi MOFA-Adapters

4. Training Pipeline
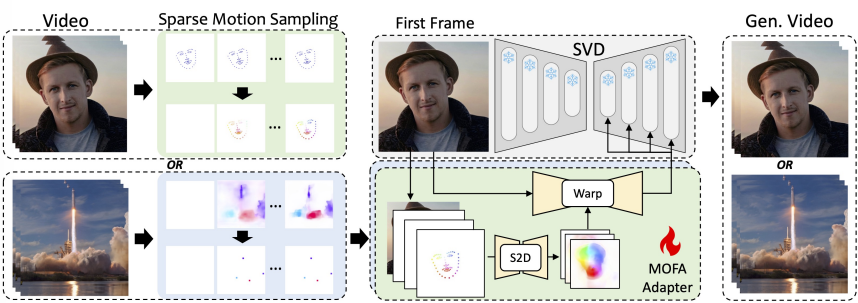
- 비디오 클립 준비 : L개의 프레임으로 이루어진 비디오 클립
Sparse Motion Vector 추출
- human motion인 경우 : face landmark와 같은 구조적 키포인트 추출
- open domain인 경우 : dense optical flow(비디오의 각 프레임 사이에서 모든 픽셀이 어떻게 이동하는지 보여줌)에서 필요한 일부 포인트만 골라내서 추출
=> 비디오에서 중요한 모션 정보를 추출하여 이를 네트워크가 학습할 수 있도록 준비하는 과정
Sparse Motion Vectors from Dense Optical Flow
- Dense Optical Flow 추출: Unimatch를 사용하여 비디오 프레임 간의 forward flow를 추출
- Point Sampling : 각 프레임에서 중요한 몇 개의 포인트 선택 (Watersheds 전략)
*Watershed sampling 전략 (물 퍼짐 시물레이션)
- 이미지의 각 픽셀의 밝기 값을 지형의 높이로 간주 (밝은 픽셀은 높은 지형, 어두운 픽셀은 낮은 지형)
- 저지대에서 물이 시작하여 주변 픽셀로 퍼져 나감
- 퍼져 나가는 물은 낮은 지형을 따라 흐르고, 고지대(밝은 픽셀)로 퍼져 나가지 않음
- 물이 퍼져 나가면서 서로 다른 저지대에서 시작된 물이 만나는 지점들이 경계를 형성
- 분할된 각 영역에서 대표적인 포인트 선택

- Mask 생성: 샘플링된 포인트는 1, 나머지는 0으로 설정된 Mask를 생성
- Sparse Motion Vector 계산: Mask를 사용하여 중요한 포인트의 움직임만을 포함하는 벡터를 생성
Sparse Motion Vectors from Structural Human Key-Points
- 얼굴의 눈,코,입(landmark) 같은 키포인트를 사용하여 프레임 간의 움직임을 추적
- 각 프레임의 landmark 간의 차이를 사용하여 Sparse Motion Vector를 생성
Loss Fuction
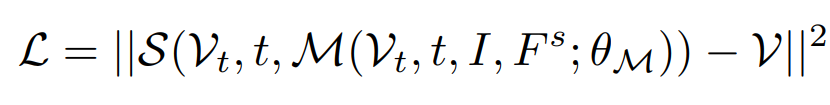
3. Result


Reference
'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] VAE 논문 리뷰 (0) | 2024.07.26 |
|---|---|
| [X:AI] Detr 논문 리뷰 (1) | 2024.07.23 |
| [D&A] GAN 논문 리뷰 (1) | 2024.07.17 |
| [X:AI] SimCLR 논문 리뷰 (2) | 2024.07.14 |
| [X:AI] Grad-CAM 논문 리뷰 (1) | 2024.07.06 |



