GoogLeNet은 2014년 ILSVRC에서 VGGNet을 제치고 우승을 차지한 모델이다.
이름에서 알 수 있듯이 구글이 해당 모델 개발에 참여했다.
해당 논문을 통해 GoogLeNet의 구조와 특징을 알아보고 VGGNet과의 차별점을 알아보고자 한다.
Introduction
- 지난 3년간(2012~2015) CNN 분야 놀라운 속도로 발전
- 이는 하드웨어 발전, 더 큰 데이터세트 뿐만 아니라 새로운 알고리즘에 대한 아이디어의 결과
- GoogLeNet은 AlexNet보다 12배 적은 매개변수 사용, but 더 정확(딥 아키텍처와 고전적인 컴퓨터비전의 시너지효과)
- GoogLeNet은 순수한 학문적 호기심을 넘어 알고리즘의 효율성(전력 및 메모리 사용량) 중요시 여김
- 이를 통해 Mobile 및 Embedded 환경에 적용가능
- GooLeNet은 심층(Deep) 신경망 아키텍처인 'Inception'에 초점
Deep의 두 가지 의미
1) 'Inception Module'의 형태로 새로운 형태의 조직 도입
2) 네트워크의 깊이가 증가한다는 직접적인 의미
Related Work
- LeNet-5 이후 CNN은 Conv layer + 하나 이상의 FC로 이어지는 표준 구조를 가지게 됨
- 대규모 데이터 세트(ImageNet)의 경우 Dropout 사용하면서 layer 수와 크기를 늘리면서 과적합 해결 노력
- GoogLeNet도 이와 같은 구조
- 1X1 Conv layer 추가하여 ReLU 활성화함수가 뒤따름
*두 가지 목적(1x1)
1) 병목현상을 제거하기 위한 차원 축소
2) 성능의 큰 영향을 주지 않으면서도 네트워크의 깊이 뿐만 아니라 폭도 늘릴 수 있음
Motivation and High Level Considerations
- 심층 신경망의 성능을 개선하는 가장 간단한 방법은 신경망의 크기(깊이와 폭)를 늘리는 것
But
- 1)신경망의 크기가 클수록 더 많은 수의 파라미터 존재 -> 특히 학습데이터 수가 적을 경우 과적합 가능성 증가
- 2) 네트워크 크기가 균일하게 증가하면 컴퓨터 리소스 사용이 급격히 증가한다는 단점
두 문제를 모두 해결하는 근본적인 방법
-> fully connected를 sparsely connected 구조로 전환
- 데이터 세트의 확률 분포가 매우 희박한 대규모 심층 신경망으로 표현되는 경우
- 마지막 층 활성화의 상관 통계를 분석을 함
- 그 후, 상관관계가 높은 뉴런을 클러스터링하여 계층별 최적의 네트워크 토폴로지 구성

But
- 오늘날의 컴퓨팅 인프라는 sparse 데이터에 대해 매우 비효율적
- Dense data는 꾸준히 개선되고 고도로 조정된 수치 라이브러리와 CPU 및 GPU의 사용으로 빠른 연산 가능해짐
- 반면, Sparse data의 연산은 발전이 미미 (격차는 더욱 커짐)
=> 따라서, sparse matrix를 효율적으로 계산하기 위해 상대적으로 밀도가 높은 하위 dense matirx들로 클러스터링
Architectural Details
Inception의 주요 아이디어
- CNN에서 각 요소를 최적의 local sparse structure를로 근사화하고, 이를 dense component로 바꾸는 방법을 찾는 것
- 결론적으로, 해야할 것은 최적의 local construction을 찾고 이를 반복하는 것
- 논문에서는 local construction을 1x1, 3x3, 5x5 convolution과 pooling이 들어가고, 이를 concatenate
- 입력과 가까운 낮은 layer에서는 local region에 집중 -> 1x1 Conv로 처리할 수 있음
- But, 고차원의 layer로 갈수록 연관된 유닛끼리 cluster되면서 lareger region에 집중
- -> 3x3, 5x5 Conv 포함 => 즉, 여러 관점에서 feature를 추출하기 위한 것

- But, 3x3, 5x5 Conv에 대해 파라미터 수가 급격하게 늘어나 연산량이 급격하게 증가
- 해당 문제 해결을 위해 1x1 Conv을 추가하여 차원 축소
GoogLeNet

- Inception module 내부를 포함하여 모든 Convolution은 ReLU 활성화 함수 사용
- receptive field 크기는 mean subtraction이 적용된 RGB 채널을 사용하는 224x224
- '#3x3 reduce' 및 '#5x5 reduce' = 3x3 및 5x5 Conv 앞에 사용된 1x1 필터의 채널 수
- pool proj = max pooling layer 뒤에 오는 1x1 필터의 채널 수
GoogLeNet 세분화
(1) Convolution Part
- Inception Module에 들어가기 전에 Conv 연산 수행
- 표에서 inception(3a)에 들어가기 전

(2) Inception Module
- Inception 연산 과정을 거친 후, DepthConcat을 통해 각기 다른 연산 합침
- 표에서 모든 inception에 적용

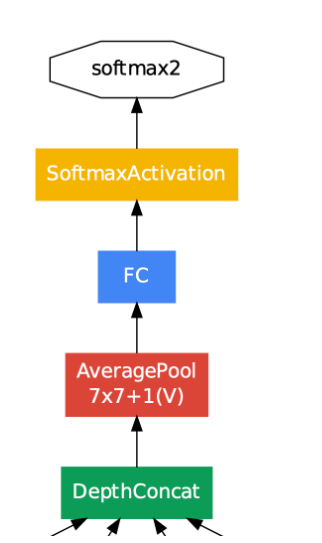
(3) Auxiliary Classifier
- 기울기 소실 문제를 보조 분류기를 넣음으로써 기울기를 강화하여 해결
- 보조 분류기는 inception(4a)와 inception(4d) 결과에 적용

(4) 최종 결정
- inception(5b) 과정이 끝났을 때, 최종 결과 출력
Training Methodology
- 0.9 momentum의 Stochastic gradient descent 이용
- learning rate는 8 epochs마다 4% 감소
- 가로, 세로 비율 3:4와 4:3 사이로 유지하며 본래 사이즈의 8%~100%가 포함되도록 다양한 크기의 patch 사용
- photometric distortions 통해 학습 데이터 늘림
Conclusions
- Inception 구조는 Sparse 구조를 Dense 구조로 근사화하여 성능을 개선
- 이는 기존 CNN 성능을 높이기 위한 방법과는 다른 새로운 방법
- 성능은 대폭 상승하지만 연산량은 약간만 증가한다는 장점
'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] InceptionV2/3 논문 리뷰 (0) | 2024.03.14 |
|---|---|
| [X:AI] SPPNet 논문 리뷰 (0) | 2024.03.10 |
| [VGG] 24.01.23 스터디 (논문) (0) | 2024.01.21 |
| [LeNet] 24.01.19 스터디 (논문) (1) | 2024.01.19 |
| [AlexNet] 24.01.16 스터디 (논문) (1) | 2024.01.15 |



