VGGNet은 ILSVRC 2014 대회에서 2등을 차지한 CNN 모델로 네트워크의 깊이가 모델의 정확도 향상에 중요한 역할을 한다는 것을 보여줬다. VGGNet의 주요 특징은 아래와 같다.
- 3X3 크기의 Conv 필터 고정적으로 사용
- 16~19개 weight layers 사용(네트워크 깊이)
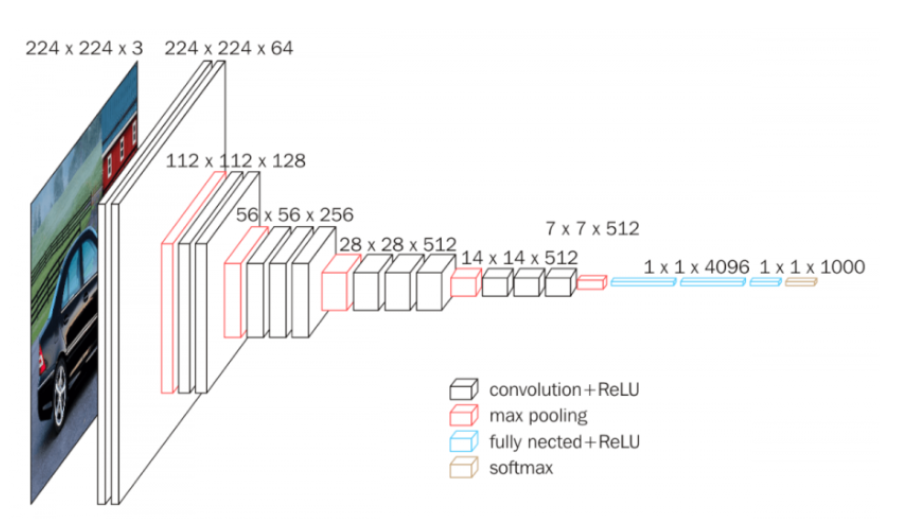
Architecture
1) Input data는 고정된 크기의 224 x 224 RGB 이미지
- 유일한 사전 처리 작업은 train set에서 평균 RGB 값을 각 픽셀에서 빼는 것
2) 3x3 크기의 Conv 필터 고정적으로 사용
- 왼쪽/오른쪽, 위/아래, 중앙의 개념을 포착할 수 있는 가장 작은 크기
- stride= 1, padding= 1
- 1x1 Conv 필터도 사용 -> layer 증가에 따른 비선형 함수 사용 빈도도 증가로 모델의 특징 식별성 향상
3) Pooling
- Max pooling
- 일부 Conv layer에 적용
- 2x2 필터, stride=2
4) 3개의 FC layer
- 1,2 layer는 4,096개의 채널
- 3 layer는 1,000개의 채널(카테고리 수)
5) 활성화 함수
- 모든 hidden layer에서 ReLU 함수 사용
- 마지막 layer에서만 Softmax 함수 사용(분류 문제)
6) AlexNet에서 적용한 LRN 사용 X
* NOTE
- VGG 이전 CNN을 활용하여 이미지 분류에서 좋은 성과를 낸 모델들은 11x11필터나 7x7 필터 사용
- 그러나, VGG는 3x3 크기의 작은 필터를 사용했음에도 정확도를 비약적으로 개선
- 3차례의 3x3 Conv을 반복한 특징맵은 한 픽셀이 원본 이미지의 7x7 Receptive field의 효과를 볼 수 있음

[3x3 필터의 이점]
1) 결정 함수의 비선형성 증가
- 1-layer 7x7 필터링은 ReLU 함수(비선형) 한 번 적용
- 3-layer 3x3 필터링은 ReLU 함수(비선형) 세 번 적용하여 비선형성 증가
- 비선형성 증가 = 모델의 식별성 증가
2) 학습 파라미터 수의 감소
- 7x7 필터 1개의 파라미터 수 = 49
- 3x3 필터 3개의 파라미터 수 = 3x3x3 = 27(차이 22개)

- 총 6개의 구조(A, A-LRN, B, C, D, E)를 만들어 깊이의 변화에 따른 성능 변화를 비교
- 11 Layer(8 Conv, 3 FC) ~ 19 Layer(16 Conv, 3 FC)
- Channels은 64에 시작해서 512까지 증가
Training
- batch size : 256
- momentum : 0.9
- weight decay(L2 penalty) : 0.0005
- dropout : FC layer 1,2에 적용, 50% 확률
- learning rate : 처음엔 0.01 이후, validation셋의 accuracy 향상 없으면 1/10씩 감소(총 3번 감소)
- epoch : 74(370K iter)
본 논문에서는 AlexNet보다 신경망이 깊고, parameter도 좀 더 많지만, 더 적은 epoch를 기록한 것은 implicit regularisation 과 pre-initialisation 때문이라고 언급
[pre-initialisation]
네트워크 가중치를 잘못 초기화하면 딥넷의 경사도가 불안정해져 학습이 지연될 수 있음
- 해당 문제를 피하기 위해 상대적으로 얕은 11-weight layer부터 학습
- 처음 4개의 Conv layers와 3개의 FC layer의 weight 값을 학습시킬 더욱 층이 깊은 네트워크에 적용
- 무작위 초기화 경우 정규분포에서 가중치 샘플링
[Training image size]
- Input image size는 224x224로 고정
- crop된 이미를 무작위로 수평 뒤집기
- 무작위로 RGB 값 변경하기
1) single-scale training
- S(=training scale)를 256 또는 384로 고정
- 먼저 S=256을 사용하여 네트워크 훈련
- S=384 네트워크의 훈련 가속화 위해 S = 256으로 사전 훈련된 가중치로 초기화하고 learning rate를 10^-3으로 줄임
2) multi-scale training
- S를 일정 범위 [256, 512]에서 무작위로 샘플링하여 재조정
- scale jittering에 의한 data augmentation으로 볼 수 있음
- 속도 문제로 인해 S = 384로 사전 훈련시킨 후 무작위로 S를 선택해 fine-tuning

Testing
- Q로 Rescale(S와 같은 필요 X)
- FC를 Conv layer로 변환
- 첫 번째 FC layer를 7x7 conv layer로 바꾸고, 마지막 두 FC layer를 1x1 conv layer로 바꿈
Single Scale Evaluation
- test image size 고정 (S=Q / 0.5(256+512)=384)
- 모델 A에 LRN을 적용한 결과 큰 성능향상이 없어 나머지 모델에서는 LRN을 적용 X
- ConvNet 깊가 증가할수록 classification error가 감소
- scale jittering이 더 좋은 성능을 보임

Multi Scale Evaluation
- test image를 multi scale로 설정
- 동일한 모델 학습에서 scale jittering을 적용한 것이 single scale 대비 더 좋은 성능을 보임

Comparison with the state of the art
- 저자는 ILSVRC 대회에 모델 성능을 제출할 때 7개 모델의 ensemble 기법을 적용.
- 최종적으로 VGGNet은 2014 ILSVRC에서 2등을 차지.

'논문 리뷰 > CV' 카테고리의 다른 글
| [X:AI] InceptionV2/3 논문 리뷰 (0) | 2024.03.14 |
|---|---|
| [X:AI] SPPNet 논문 리뷰 (0) | 2024.03.10 |
| [GoogLeNet] 24.01.23 스터디 (논문) (0) | 2024.01.23 |
| [LeNet] 24.01.19 스터디 (논문) (1) | 2024.01.19 |
| [AlexNet] 24.01.16 스터디 (논문) (1) | 2024.01.15 |



