[X:AI] RetinaNet 논문 리뷰
논문 원본 : https://arxiv.org/abs/1708.02002
Focal Loss for Dense Object Detection
The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampl
arxiv.org
1. Abstract & Introduction
- 본 논문 시점 기준 Object Detection 모델들은 대부분 Two-stage 방식의 제안 기반(Proposal-Driven) 매커니즘을 사용
- 대표적인 예로 R-CNN 프레임워크
- 첫 번째 단계 : 객체가 있을 가능성이 있는 후보 영역 (Proposal)을 생성
- 두 번째 단계 : 각 후보 영역을 CNN을 이용해 분류하여 배경인지, 특정 객체인지 판단
One-Stage로도 동일한 성능을 이끌어 낼 수 있는가
- 기존의 One-Stage Detection 모델들은 객체가 있을 가능성이 있는 모든 위치를 균일하게 샘플링하여 한 번의 과정으로 바로 객체를 탐지
- 대표적인 모델로 YOLO와 SSD가 있음
- 이러한 One-Stage 모델들은 더 빠른 속도를 제공하지만, 기존 Two-Stage 모델보다 정확도가 낮음(10~40% 차이)
- 본 논문에서는 이를 더욱 발전시켜, One-Stage 방식이면서도 Two-Stage 방식과 동일한 수준의 성능을 내는 새로운 객체 탐지 모델을 제안 (새로운 손실함수 Focal Loss 제안)
기존 One-Stage 문제점 : Class Imbalance
- 기존의 Two-Stage 모델들은 클래스 불균형 문제(배경>객체)를 후보 영역 추출 단계에서 해결할 수 있음
- 예를 들어, Faster R-CNN 같은 모델은 RPN을 사용해 객체가 있을 확률이 높은 영역만 선택하고 불필요한 배경 영역을 대부분 제거
- 하지만, One-Stage 모델은 이미지 전체를 대상으로 모든 위치에서 객체를 찾기 때문에 배경 영역이 너무 많아 학습이 비효율적으로 진행
- 배경만 맞추는 것만으로도 높은 정확도 기록
- 즉, 모델이 "객체를 찾는" 학습을 하지 않고, "배경을 제외하는" 학습만 하게 되는 문제 발생
- 기존에는 이를 해결하기 위해 샘플링 기법(sampling heuristics) 또는 어려운 예제 학습(hard example mining)을 적용했지만, 이러한 방법은 효율적이지 못했음
해결책 : Focal Loss
- 본 논문에서는 기존 방법보다 더 효과적인 Focal Loss라는 새로운 손실 함수를 제안
- Focal Loss는 Cross-Entropy Loss (일반적인 분류 손실 함수)를 개선한 방식
- 쉽게 분류되는 예제 (ex. 배경 영역)에 대해서는 손실 값이 자동으로 줄어들고
- 반대로 어려운 예제 (ex. 객체 영역)에 대해서는 손실이 커지도록 조절
- 즉, 모델이 쉬운 예제보다 어려운 예제에 더 집중하도록 유도
- 이러한 방식으로 Focal Loss를 적용하면, 기존의 샘플링 기법이나 hard example mining보다 훨씬 효율적인 학습이 가능해짐
- 실험 결과, Focal Loss를 적용하면 One-Stage Detection 모델이 기존의 Two-Stage 모델을 능가하는 성능 달성
RetinaNet : 최적화된 One-Stage Detection Model
- 본 논문은 Focal Loss를 활용한 새로운 One-Stage Detection 모델인 "RetinaNet"을 개발
- RetianNet은 다음과 같은 성능을 기록
- ResNet-101 + FPN 백본(Backbone)을 사용한 RetinaNet 모델
- COCO 데이터셋에서 AP 39.1의 성능 달성
- 초당 5장(5 FPS) 속도로 실행 가능
- 기존의 Two-Stage 모델보다 높은 성능을 기록
- ResNet-101 + FPN 백본(Backbone)을 사용한 RetinaNet 모델

2. Related Work
Classific Object Detectors
- 과거 객체 검출은 sliding-window 방식이 주로 사용되었음
- 이 방식에서는 작은 창(sliding window)을 이미지 전체에 걸쳐 움직이며, 특정 사물이 있는지를 검사하는 방법
- 하지만, 딥러닝이 발전하면서 슬라이딩 윈도우 방식은 점차 2-stage 검출기로 대체
Two-stage Detectors
- 현재 많이 사용하는 객체 검출 방법 중 하나는 2단계 접근법
- 1단계: 후보 영역(Region Proposal)을 생성하여, 객체가 있을 가능성이 높은 위치를 찾음
- 2단계: 이 후보 영역을 CNN을 활용해 분류하고, 최종 객체를 판별
- R-CNN: 기존 검출기보다 훨씬 정확한 결과를 보이며, 객체 검출 분야를 발전시킴
- Fast R-CNN & Faster R-CNN: R-CNN의 속도를 개선하여, 딥러닝 기반 객체 검출 모델의 표준이 되었음
- Region Proposal Network (RPN): Faster R-CNN의 핵심 기술로, 후보 영역을 생성하는 과정을 CNN 내부에 포함하여 속도를 크게 향상시킴
One-stage Detectors
- one-stage 객체 검출 방식은 two-stage 방식을 개선하여 속도를 높이기 위해 고안되었음
- OverFeat: 최초의 딥러닝 기반 one-stage 검출 모델
- SSD & YOLO: 최근에는 SSD와 YOLO가 대표적인 one-stage 검출기로 사용됨
- SSD: 빠르지만, 기존 2-stage 검출기보다 성능이 다소 떨어짐 (정확도 10-20% 낮음)
- YOLO: 속도를 극단적으로 높이는 대신, 정확도를 일부 희생한 모델
- RetinaNet 모델에서는 1-stage 방식의 주요 단점인 클래스 불균형 문제를 해결하여 성능을 높이고자 함
Class Imbalance
- 객체 검출에서 가장 큰 문제 중 하나는 객체가 없는 배경(negative location)이 너무 많아 학습이 어려워지는 것
- 1-stage 검출기는 한 이미지에서 10만 개 이상의 후보 위치를 검사하지만, 실제로 객체가 있는 곳은 몇 개뿐
- 모델이 쉽게 구분되는 배경(negative samples)에 치우쳐 학습되면, 어려운 샘플(positive)을 제대로 학습하지 못함
기존 해결책
- Hard Negative Mining: 어려운 배경(negative) 샘플만 골라 학습
- 가중치 조절(Re-weighting): 중요한 샘플에 가중치를 줘서 학습 효과를 높임
RetinaNet의 해결책
- RetinaNet에서는 새로운 손실 함수인 Focal Loss를 사용하여 문제를 해결
Robust Estimation
- 기존의 Huber Loss 같은 로버스트 손실 함수는 특정 샘플이 너무 큰 영향을 미치는 것을 방지하는 방식
- 하지만, RetinaNet의 Focal Loss는 반대로 너무 쉬운 샘플들의 영향을 줄이고, 어려운 샘플에 집중하도록 하는 역할
기존 방법 (Huber Loss)
- 이상치(outlier) 샘플의 영향을 줄이기 위해 설계됨
Focal Loss
- 어려운 샘플(hard examples)에 집중하기 위해 설계됨
- 쉬운 샘플(easy examples)은 영향력을 줄이고, 어려운 샘플의 기여도를 높임
3. Focal Loss
Cross Entropy Loss 문제점
- 이미 잘 분류된 샘플(쉬운 샘플)이 전체 손실 값에서 차지하는 비율이 너무 커서 어려운 샘플이 충분히 학습되지 않는 문제가 발생




3.1 Balanced Cross Entropy
- 이를 해결하기 위해, 클래스 불균형을 고려하여 Cross Entropy Loss 수정
- 각 클래스의 중요도를 값으로 조절
- 여기서 값은 희귀한(=적게 나오는) 클래스에 더 높은 가중치를 부여하는 방식으로 설정
- 하지만 해당 방식은 "클래스별 중요도"만 고려할 뿐, 개별 샘플의 난이도를 고려하지 않음

3.2 Focal Loss Definition
- Focal Loss는 쉬운 샘플의 영향력을 줄이고, 어려운 샘플에 집중하는 방식을 추가
- (감쇠 계수, Focusing Parameter) 값이 클수록, 쉬운 샘플의 손실을 더 강하게 줄임
- 값이 작으면 (= 어려운 샘플이면)
- 값이 거의 1이 되어, 손실 값이 그대로 유지됨
- 즉, 잘못 예측한 샘플(어려운 샘플)에는 큰 손실을 부여하여 모델이 학습할 수 있도록 유도함
- 값이 크면 (= 쉬운 샘플이면)
- 값이 작아져서 손실이 거의 0이 됨
- 즉, 이미 잘 분류된 샘플의 손실을 감소시켜, 어려운 샘플 학습에 집중하도록 함

- Focal Loss는 위의 클래스 불균형 보정(α) 방법도 함께 적용할 수 있음
- 정도가 일반적으로 좋은 성능을 보임

3.3 Class Imbalance and Model Initialization
- binary classification model은 기본적으로 또는 을 출력할 확률이 동일하도록 초기화
- 그러나 클래스 불균형(class imbalance)이 존재할 경우, 자주 등장하는 클래스(frequent class)에 의해 손실(loss)이 지배되어 학습 초기에 불안정성이 발생할 수 있음
- 이를 해결하기 위해, 희귀 클래스에 대한 확률 의 초기값을 조정하는 '사전 확률(prior)' 개념을 도입
- 이 사전 확률을 라고 하며, 모델이 희귀 클래스의 확률을 낮게 예측하도록 설정
- 예를 들어, 초기 확률을 0.01로 설정
3.4 Class Imbalance and Two-stage Detectors
- 일반적인 two-stage detector는 cross entropy loss 사용
- 클래스 불균형을 해결하기 위해 α-balancing이나 새로운 손실 함수를 적용하지 않음
- 대신 다음 두 가지 방법을 사용
- 첫 번째 단계는 object proposal 과정으로, 무한한 객체 위치 후보 중에서 1,000~2,000개 정도만 선택
- 이 과정에서 대부분의 "쉬운 음성 샘플(easy negatives)"을 제거
- 두 번째 탐지 단계를 학습할 때, 미니배치를 구성할 때 양성(positivie) 샘플과 음성(negative) 샘플의 비율 조정
- 예를 들어, 1:3 비율(양성 1개당 음성 3개)로 샘플을 구성하면, 이는 마치 α-balancing을 구현하는 것과 같은 효과를 냄
- 첫 번째 단계는 object proposal 과정으로, 무한한 객체 위치 후보 중에서 1,000~2,000개 정도만 선택
- Focal Loss는 이러한 2단계 탐지기의 균형 조정 방식을 1단계 탐지기(one-stage detector)에서도 적용할 수 있도록 설계됨
- 1단계 적용
- Focal Loss 는 배경 샘플이 너무 쉽게 맞춰지면 손실을 작게 만들어 학습에서 무시함
- 즉, "쉬운 음성(negative) 샘플을 제거하는 효과"를 손실 함수에서 구현한 것
- 2단계 적용
- Focal Loss 는 어려운 샘플일수록 손실을 키워 학습을 더 강화하도록 설계됨
- 즉, "객체(positive) 샘플을 더 강조하는 효과"를 손실 함수에서 구현한 것
- 1단계 적용
4. RetinaNet Detector
- RetinaNet은 하나의 통합된 네트워크로, 크게 backbone network와 두 개의 subnetworks로 구성됨
- backbone network : 이미지 전체에서 특징(feature) 을 추출하는 역할을 하며, 기존에 존재하는 CNN(합성곱 신경망) 구조를 그대로 사용
- 첫 번째 subnetwork : 객체 분류(object classification) 를 수행
- 두 번째 subnetwork : 바운딩 박스 회귀(bounding box regression) 를 수행하여 객체의 위치를 예측
Feature Pyramid Network Backbone
- RetinaNet은 FPN(Feature Pyramid Network) 구조를 Backbone으로 사용
- FPN은 기존 CNN을 위에서 아래(top-down) 로 연결하여 다양한 크기의 객체를 탐지할 수 있도록 도와줌
- FPN은 ResNet을 기반으로 하며, P3~P7 수준의 피라미드(feature pyramid levels) 를 생성
- P3~P7의 해상도는 점점 작아지며(해상도가 2l배 감소), 작은 객체부터 큰 객체까지 탐지할 수 있도록 설계
- P6, P7은 P5, P6을 downsampling 해서 사용
- 각 레벨은 256채널(C=256) 을 사용함
- P3~P7의 해상도는 점점 작아지며(해상도가 2l배 감소), 작은 객체부터 큰 객체까지 탐지할 수 있도록 설계
- FPN은 ResNet을 기반으로 하며, P3~P7 수준의 피라미드(feature pyramid levels) 를 생성
- 만약 FPN 없이 ResNet의 마지막 계층만 사용하면 탐지 성능(AP, Average Precision)이 낮아짐
FPN 논문 : https://arxiv.org/abs/1612.03144
Feature Pyramid Networks for Object Detection
Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, w
arxiv.org
Anchors
- RetinaNet은 anchor box 를 사용하여 객체를 탐지
- anchor box는 고정된 크기의 박스 를 말하며, 이미지의 다양한 위치에서 객체를 찾을 때 사용됨
- P3~P7 피라미드 레벨마다 크기가 다른 앵커 박스 를 배치하여 다양한 크기의 객체를 탐지 할 수 있도록 설계됨
- anchor 크기: 32×32 ~ 512×512
- 3가지 종횡비(aspect ratio) 사용: {1:2, 1:1, 2:1}
- 추가적인 스케일(scale) 적용: {20, 21/3, 22/3}
- 최종적으로 레벨당 9개의 anchor(A=9) 를 사용하여 32~813 픽셀 범위의 객체를 탐지 가능
- 각 anchor는 클래스 레이블(K개) + 박스 좌표(4개)로 표현
Classification Subnet
- 객체가 존재할 확률을 예측하는 역할을 함
- FPN의 각 피라미드 레벨에 붙어 있는 작은 Fully Convolutional Network (FCN) 구조
- 구조
- 4개의 3×3 Conv Layer (C=256 채널, ReLU 활성화 사용)
- 마지막 3×3 Conv Layer (KA개의 필터)
- Sigmoid 활성화 함수로 확률 출력
- RPN(Region Proposal Network)과 달리, 더 깊고 3×3 컨볼루션만 사용하며, box regression subnet과 파라미터를 공유하지 않음
Box Regression Subnet
- 각 anchor가 실제 객체 박스와 얼마나 차이가 있는지를 예측하는 역할을 함
- 구조는 classification subnet과 동일하지만, 최종 출력이 다름
- 4개의 3×3 Conv Layer (C=256 채널, ReLU 활성화 사용)
- 마지막 3×3 Conv Layer (4A개의 필터)
- 최종적으로 각 anchor에 대해 4개의 좌표값을 예측 (x, y, w, h 변환값)
- 구조는 classification subnet과 동일하지만, 최종 출력이 다름
- 기존 방식과 달리, 클래스-독립적인(class-agnostic) 회귀 모델을 사용하여 파라미터 수를 줄임

4.1 Inference and Training
Inference
- 추론 속도를 높이기 위해 다음과 같은 최적화 기법을 적용
- FPN(FPN의 각 레벨)에서 감지된 객체들 중 점수가 가장 높은 1000개만 남김 (Confidence Threshold 0.05 이상)
- 모든 레벨에서 나온 예측을 합친 후(5000개), NMS를 수행하여 최종 객체를 결정 (NMS Threshold: 0.5)
Focal Loss
- 실험 결과, γ = 2일 때 가장 성능이 좋았고, γ 값이 0.5~5 범위에서 비교적 안정적인 성능을 보임
- α(rare class 가중치) 값은 γ와 함께 조정해야 하며, 일반적으로 γ 값이 증가하면 α 값을 약간 감소시켜야 함
- γ=2일 때, α=0.25가 최적값으로 나타남

Initialization
- RetinaNet의 백본 네트워크로 ResNet-50-FPN 및 ResNet-101-FPN을 사용
- ResNet-50 및 ResNet-101은 ImageNet1K 데이터셋으로 사전학습(pretrained)된 모델을 사용
- 모든 새로운 합성곱(conv) 레이어는 평균 0, 표준편차 0.01의 가우시안(Gaussian) 분포로 초기화 (단, 마지막 conv 제외)
- 마지막 classification subnet의 Conv Layer는 특별히 b = − log((1 − π)/π) 형태로 bias를 초기화
- 여기서 π는 학습 시작 시 모든 anchor가 배경일 확률 (=객체가 존재하지 않을 확률)
- 실험에서는 π=0.01을 사용 (모델이 처음부터 anchor의 99%를 배경으로 예측하도록 유도)
- 이러한 초기화 방식은 배경 anchor의 비율이 높아 초기 손실이 폭발하는 문제를 방지하는 역할을 함
5. Experiments
5.1 Training Dense Detection
- ResNet-50/101 + FPN 사용
- 기본 Cross Entropy(CE) Loss는 학습 실패 → Prior 확률(π=0.01) 적용 후 AP 30.2 달성
- α-balanced CE Loss(α=0.75) 사용 시 0.9 AP 상승
- Focal Loss(FL, γ=2.0, α=0.25) 적용 시 AP 36.0으로 성능 향상 (α=0.5도 유사한 성능)
5.2 Model Architecture Design
- Anchor Density: 3개의 스케일 + 3개의 종횡비 사용 시 AP 34.0 달성 (4 AP 증가)
- 6~9개 이상의 anchor를 사용해도 추가 성능 향상 없음

5.3 Comparison to State of the Art
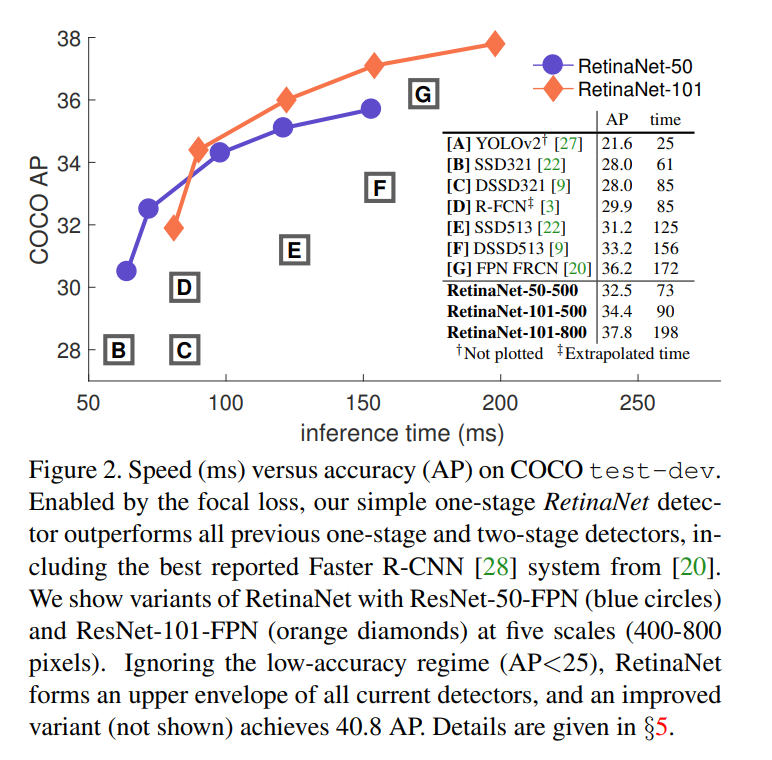
- RetinaNet-101-800 (스케일 조정 및 학습 증가) → AP 39.1 달성 (기존 33.2보다 5.9 AP 증가)
- Faster R-CNN (Inception-ResNet-v2-TDM) 대비 2.3 AP 우수한 성능
- ResNeXt-32x8d-101-FPN 백본 적용 시 AP 40+ 돌파

6. Conclusion
- Class Imbalance이 One-Stage 객체 검출기의 성능을 제한하는 주요 원인이라고 분석함
- 이를 해결하기 위해 Focal Loss를 제안, 기존 Cross Entropy Loss에 조절 항(modulating term)을 추가하여 Hard Negative 예제에 더 집중하도록 학습함
- 제안한 방법은 단순하면서도 효과적이며, 완전 합성곱(fully convolutional) 기반 원스테이지 검출기를 설계하여 실험적으로 검증함
- 실험 결과, 최신(two-stage) 방식과 비교해 정확도와 속도에서 우수한 성능을 달성함