[X:AI] YOLO 논문 리뷰
논문 원본 : https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
Abstract
- 이전 연구들은 객체 탐지를 위해 분류 모델을 변형해 사용했지만, 우리는 객체 탐지를 회귀 문제로 재구성하여, 이미지 내의 경계 상자와 해당 클래스 확률을 예측
- 단일 신경망이 한 번의 평가만으로 전체 이미지를 분석하고 경계 상자와 클래스 확률을 예측 (One-Stage Detector)
- YOLO는 탐지 파이프라인 전체를 하나의 신경망으로 통합했기 때문에 탐지 성능을 기준으로 End-to-End 최적화 가능
- YOLO는 매우 빠르며 기본 모델은 초당 45 프레임으로 실시간 처리가 가능하며, 더 작은 Fast YOLO는 놀랍게도 155 프레임을 처리하면서도 다른 실시간 탐지기보다 두 배 높은 mAP 성능을 달성
- 최신 탐지 시스템과 비교했을 때, YOLO는 물체 위치를 정밀하게 잡아내는 데 약간 부족할 수 있지만, 배경과 객체를 잘 구분하고 여러 도메인에서 객체 탐지 가능
1. Introduction
- 기존 객체 탐지 시스템들은 보통 분류 모델을 번형해서 탐지 수행
- 예를 들어, DPM(Deformable Part Models) 같은 시스템은 이미지 전체를 탐색하면서, 각 위치와 크기에서 분류기를 실행. 이런 방식을 슬라이딩 윈도우(sliding window) 방식이라고 함
- 반면, R-CNN은 후보 영역(Region Proposal)을 찾아내고, 그 후보들에 대해 분류기를 실행
- 이 과정이 끝나면, 경계 상자(Bounding Box)를 조정하거나 중복 탐지를 제거하고, 물체 간 상호작용을 고려해 점수를 다시 매기는 후처리(Post-Processing)가 필요
- 문제는 이런 방식들이 과정이 복잡하고 느리며, 각 단계별로 따로 학습해야 한다는 점
- YOLO는 객체 탐지를 이미지 픽셀에서 바로 bounding box 좌표와 class 확률을 예측하는 단일 회귀 문제로 재구성
- 이 시스템을 통해 이미지를 한 번만 보고 어떤 물체들이 어디에 있는지를 예측할 수 있음
- YOLO는 단일 컨볼루션 신경망(Convolutional Neural Network)을 사용해 여러 bounding box 와 그 class 확률을 동시에 예측
- 슬라이딩 윈도우나 지역 제안(Region Proposal) 기반 기법은 이미지 일부만 보기 때문에 물체의 문맥적 정보(Context)를 놓치기 쉬움
- YOLO는 탐지 파이프라인이 복잡하지 않아서 매우 빠름
- 기본 YOLO 모델은 Titan X GPU에서 초당 45프레임(45 fps)을 처리하며, 빠른 버전(Fast YOLO)은 초당 150프레임 이상을 처리
- YOLO는 물체의 일반적인 표현(Generalized Representations)을 학습
- 새로운 데이터 도메인에서도 좋은 성능을 보임
- 하지만 YOLO는 아주 정확한 위치를 잡아내는 데는 약간 약할 수 있다는 점

2. Unified Detection
- YOLO는 입력 이미지를 SxS 크기의 그리드로 나눔
- 예를 들어, PASCAL VOC에서는 로 설정되어 있으니 이미지가 7×7로 분할
- 각 그리드 셀은 B개의 Bounding Box와 그 상자들의 Confidence Score를 예측
- bounding box는 5가지 정보를 포함
- : 상자의 중심 좌표(그리드 셀 내 상대적인 위치/ 0~1)
- : 상자의 너비와 높이(전체 이미지에 대한 비율로 예측/ 0~1)
- Confidence
- P(Object) x IOUpred,truth
- P(Object) : 해당 bouding box 안에 실제로 물체가 존재할 확률
- IOUpred,truth : 예측된 bounding box와 실제 bounding box의 겹치는 부분을 기준으로 계산한 일치율
- 물체가 없다면 Confidence는 0
- 각 그리드 셀은 물체가 포함된 경우, 해당 물체가 특정 클래스일 확률 도 예측
- : 클래스의 수 (예: PASCAL VOC에서는 )
- 중요: 그리드 셀당 하나의 클래스 확률 집합만 예측하며, 상자 개수(B)와는 무관

- YOLO의 PASCAL VOC 데이터셋 실험 설정
- : 이미지를 7 × 7 그리드로 나눔
- : 각 그리드 셀이 2개의 경계 상자를 예측
- : 데이터셋에 20개의 클래스가 존재
- 최종 출력은 7 × 7 × 30 텐서로 나타남

2.1 Network Design
- YOLO의 네트워크는 GoogLeNet에서 영감을 받음
- 24개의 Convolution Layer: 이미지의 특징을 추출
- 2개의 FC Layer: 물체의 클래스와 위치를 예측
- GoogLeNet과 달리, Inception 모듈을 사용하지 않음
- 1 × 1 크기의 축소(reduction) 레이어와 3 × 3 크기의 컨볼루션 레이어를 사용
- 최종적으로, 네트워크의 출력은 7 × 7 × 30 크기의 텐서
- YOLO의 빠른 버전인 Fast YOLO는 더 작은 네트워크 구조를 사용
- 9개의 Convolution Layer: 일반 YOLO보다 적은 레이어
- 각 레이어에 적은 필터: 계산량 감소

2.2 Training
- 앞 Convolution Layer 20개는 ImageNet 100-class 데이터셋으로 사전 학습 진행
- Ren et al. 연구를 참고하여, 추가로 4개의 Conv Layer와 2개의 Fully Connected Layer를 더함
- 입력 해상도를 224×224에서 448x448로 증가시켜 더 정교한 시각 정보를 활용
- 최종 레이어는 선형 활성화 함수(linear activation) => 출력값이 직접적인 수치로 해석되어야 하기 때
- 나머지 레이어는 Leaky ReLU를 사용
Loss Function
- YOLO는 학습 과정에서 모든 bouding box를 활용하지 X
- GT box 의 중심에 위치한 grid cell만이 객체를 가짐
- 해당 responsible한 grid cell에서 IOUpred,truth가 가장 높은 bbox 1개만 사용하여 학습 진행
- ex) 17yellow,object =1 로 표시



- 합계 제곱 오차 (Sum-Squared Error) 사용
- bounding box 좌표 & 크기 loss
- 1ij,object = 1일 때만 (객체가 있는 경우에만)
- 바운딩 박스 크기에 따른 오차 차별을 없애기 위해 루트를 씌움
- bounding box confidence loss
- 1ij,object = 1 or 0일 때 둘 다 계산 (객체가 없는 경우에도)
- 클래스 확률 loss
- 이미지 대부분의 그리드 셀에는 객체가 없는 경우가 많음
- 따라서 모델은 객체가 없는 셀에서 신뢰도를 0으로 예측하는 작업에 더 집중하게 됨
- 본 taks에서는 bounding box 좌표 예측이 더 중요
- 이를 해결하기 위해 λcoord = 5, λnoobj = 0.5 설정

2.3 Inference
- Single network로 detection 가능함
- PASCAL VOC dataset 기준, 이미지 1개당 98개의 bounding box 생성 & class-specific confidence score
- object 당 bbox 개수가 많으므로 NMS 적용 필요

- class마다 class-specific confidence score 정렬 후 NMS 적용
- 각 object에 대해 예측한 여러 bbox 중에서 가장 예측력이 좋은 bbox만 남기기 위함

- 같은 class 속하는 object가 2개 이상인 경우
- bbox #12와 #13의 IOU가 높으므로 NMS에 의해 제거됨
- bbox #12와 #16의 IOU가 낮으므로 NSM에 의해 제거되지 않음


- 다른 class에 속하는 object
- class마다 class-specific confidence score 정렬 후 NMS 적용

2.4 Limitations of YOLO
- YOLO는 각 그리드 셀이 두 개의 박스만 예측하고 한 클래스만 가질 수 있기 때문에 바운딩 박스 예측에 강한 공간적 제약을 가짐
- 이 제약 때문에 모델은 가까이 있는 여러 객체를 잘 예측하지 못함
- 예를 들어, 새 떼처럼 작은 객체가 무리지어 있는 경우 문제가 발생
- 또한, YOLO는 데이터를 통해 바운딩 박스를 예측하는 법을 배우기 때문에 새로운 형태나 특이한 비율의 객체를 일반화하는 데 어려움을 겪음
- 그리고 네트워크 아키텍처가 입력 이미지를 여러 번 다운샘플링하기 때문에 바운딩 박스를 예측할 때 상대적으로 거친(coarse) 특징을 사용
- 마지막으로, YOLO는 감지 성능을 근사하는 손실 함수를 사용하여 학습하지만, 작은 바운딩 박스와 큰 바운딩 박스에서의 에러를 똑같이 취급
- 큰 박스에서의 작은 에러는 크게 문제가 되지 않지만, 작은 박스에서의 작은 에러는 IOU(교차 영역 비율)에 큰 영향을 미침
4. Experiments
4.1 Comparison to Other Real-Time Systems
- YOLO는 PASCAL VOC 2007에서 가장 빠르고 정확한 객체 탐지 모델
- Fast YOLO: 52.7% mAP로 이전 실시간 모델보다 2배 이상 정확
- VGG-16을 사용한 YOLO는 더 정확하지만 실시간 성능이 떨어짐
- Faster R-CNN: 높은 정확도를 제공하지만 속도(7fps)에서 YOLO(45fps)보다 훨씬 느림

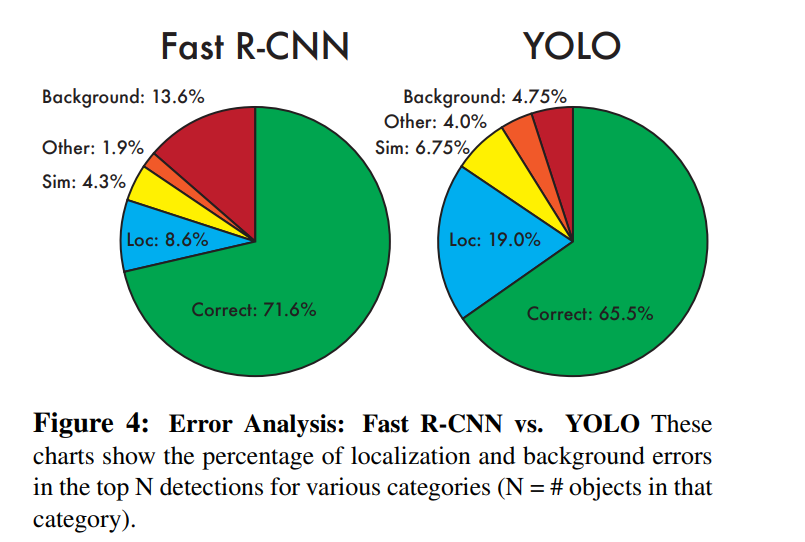
4.2 VOC 2007 Error Analysis
- YOLO의 주요 오류는 Localization Error(위치 오류): 객체의 위치를 정확히 잡지 못함
- Fast R-CNN은 Localization Error는 적지만, Background Error(배경 오류) 가 많음
- YOLO는 Fast R-CNN에 비해 배경을 객체로 오탐지하는 확률이 3배 낮음
4.3 Combining Fast R-CNN and YOLO
- YOLO를 Fast R-CNN의 배경 오류 필터로 사용해 성능 향상
- Fast R-CNN이 예측한 바운딩 박스가 진짜 객체인지 아닌지를 YOLO로 확인
- Fast R-CNN의 mAP가 71.8% → 75.0%로 3.2% 상승
- YOLO와 Fast R-CNN은 서로 다른 유형의 오류를 보완하여 성능을 극대화
- 하지만 속도는 Fast R-CNN의 느린 성능에 영향을 받음

4.4 VOC 2012 Results
- YOLO: 57.9% mAP (최신 모델보다는 낮음)
- 작은 객체(예: 병, 양, TV)에서 약점이 있지만, 큰 객체(예: 고양이, 기차)에서는 더 높은 성능을 보임
- YOLO + Fast R-CNN 결합 모델은 VOC 2012 리더보드에서 상위권에 진입

4.5 Generalizability : Person Detection in Artwork
- Picasso Dataset, People-Art Dataset에서 YOLO는 기존 모델보다 새로운 도메인에 더 잘 일반화
- R-CNN은 자연 이미지에 특화되어 있어 성능이 급격히 저하됨
- YOLO는 객체의 크기, 모양, 관계를 잘 모델링하여 예술작품에서도 성능 유지

5. Real-Time Detection In the Wild
- YOLO는 웹캠에 연결해 실시간 객체 탐지가 가능하며, 객체가 이동하고 외형이 바뀌어도 정확히 탐지
- 웹캠과 연결하면 실시간 추적 시스템처럼 작동
- YOLO의 빠르고 정확한 성능은 컴퓨터 비전 애플리케이션에 이상적

6. Conclusion
- YOLO의 특징
- YOLO는 객체 탐지를 위한 통합된 모델로, 전체 이미지를 한 번에 처리
- 기존 분류 기반 접근법과 달리, 탐지 성능에 직접적으로 연관된 손실 함수로 훈련
- 모델 전체를 통합적으로 학습하도록 설계
- 속도와 성능
- Fast YOLO: 현재 문헌에서 가장 빠른 범용 객체 탐지기
- YOLO: 실시간 객체 탐지에서 최첨단 성능을 제공하며, 속도와 정확도를 모두 갖춤
- 일반화 능력
- YOLO는 새로운 도메인(예: 예술 작품)에도 잘 일반화 가능
- 빠르고 강력한 객체 탐지가 필요한 애플리케이션에 적합
7. Reference
https://www.youtube.com/watch?v=O78V3kwBRBk
https://www.youtube.com/watch?v=84JM_q8zqh8