논문 리뷰/Multi Modal
[X:AI] DALL-E 논문 리뷰
hyeon827
2024. 8. 20. 13:48
Zero-Shot Text-to-Image Generation
논문 원본 : https://arxiv.org/abs/2102.12092
Zero-Shot Text-to-Image Generation
Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentati
arxiv.org
2. Method
Stage 1
- Discrete VAE를 사용하여 256x256 크기의 RGB 이미지를 압축
- 이 과정을 통해 이미지가 32x32 크기의 Image Token으로 압축
- 각 Token은 8192가지의 값을 가질 수 있음
- context size는 192배로 줄일 수 있음 (8x8x3)
Stage 2
- 최대 256개의 BPE(Bite Pair Encoding) 인코딩된 텍스트 토큰을 32x32 이미지 토큰과 연결
- Text & Image token의 결합 분포는 Autogressive transformer를 통해 학습됨

Overview
- 텍스트가 BPE로 인코딩되어 최대 256개의 텍스트 토큰으로 변환. 이 토콘들은 DALL-E 모델에 입력됨
- 그 후, 이미지 토큰이 최대 1024개까지 추가될 수 있음. 이 이미지 토큰들은 텍스트와 함께 모델에 입력됨
- DALL-E는 Transformer Decoder Architecture를 사용
- Transformer Decoder는 입력된 텍스트와 이미지 토큰을 받아, 다음에 생성될 이미지의 latent code를 예측
- 모델은 각 이미지 토큰이 어떤 값을 가질지 예측할 때, 가장 높은 확률을 가진 토큰이 선택되어 다음 토큰으로 사용됨

- 아래 식은 DALL-E가 이미지 x를 캡션 y와 인코딩된 이미지 토큰 z로부터 어떻게 생성하는지 설명
- 텍스트와 이미지 토큰의 결합 분포 pψ(y,z)를 통해, 주어진 텍스트 설명과 이미지 토큰으로부터 최종 이미지를 생성하는 과정 pθ(x∣y,z)을 나타냄

- dVAE의 인코더 qθ는 입력된 이미지를 32x32 이미지 토큰으로 변환
- Transformer pψ는 주어진 텍스트와 이미지 토큰의 결합 분포를 학습하여, 이들 사이의 관계를 모델링
- 최종적으로, dVAE 디코더 pθ는 Transformer에서 예측된 이미지 토큰을 바탕으로 최종 이미지 복원하여 텍스트에 맞는 이미지를 생성

2.1 Stage One : Learning the Visual Codebook
- 와 ϕ에 대해 ELBO를 Maximizing (오직 이미지 데이터만을 사용하여 학습 진행)
- Initial prior
- Discrete distribution은 연속적인 확률분포와 달리, 미분이 어려워 최적화에 어려움이 있음
- 해당 분포의 경우, 일반적인 Reparameterization gradient를 사용할 수 없음
- Gumbel-softmax는 변별 분포를 연속적인 분포처럼 처리할 수 있도록 해주는 기법
- 는 온도 파라미터로, T가 0에 가까워질수록 연속 분포가 원래의 변별 분포와 더 유사해짐
- Log-laplace distribution을 활용하여 Evaluate
2.2 Stage Two : Learning the Prior
- 텍스트와 이미지 토큰의 결합된 분포를 학습하는 과정
- 모델의 파라미터 θ와 ϕ를 고정시키고, ψ에 대한 ELBO(Evidence Lower Bound)를 최대화하면서 텍스트와 이미지 토큰의 Prior 분포를 학습
- Prior 분포를 학습하기 위해, DALL-E는 130억 개의 파라미터를 가진 Sparse Transformer를 사용
- Sparse Transformer는 효율성을 높이기 위해 일부 연결을 생략한 트랜스포머 모델로, 큰 모델을 효과적으로 학습할 수 있도록 도와줌
- 입력된 텍스트(캡션)는 모든 단어를 소문자로 변환한 후, 16384개의 단어 집합(Vocabulary)을 사용하여 BPE(Byte Pair Encoding)로 인코딩
- 이 인코딩 과정에서 최대 256개의 텍스트 토큰이 생성됩니다. BPE는 자주 등장하는 단어 쌍을 하나의 토큰으로 병합하는 방식으로, 텍스트를 압축적으로 표현할 수 있음
- 이미지 데이터는 32x32 크기의 그리드로 나뉘어 각각의 블록이 하나의 토큰으로 인코딩 ( 총 1024개의 이미지 토큰이 생성)
- 이 이미지 토큰들은 8192개의 고유한 값(잠재 코드) 중 하나로 표현
- dVAE 인코더는 이 이미지 토큰들을 인코딩하고, Argmax 샘플링을 통해 가장 가능성이 높은 이미지 토큰을 선택
- 최종적으로, 텍스트 토큰과 이미지 토큰을 하나의 시퀀스로 결합(Concatenate)하여 단일 데이터 스트림으로 만듦
- 이 결합된 시퀀스는 Autoagressive 모델링을 통해 학습
- Transformer의 디코더 아키텍처가 어떻게 텍스트와 이미지에 대해 주의를 기울이는지(attention)를 설명

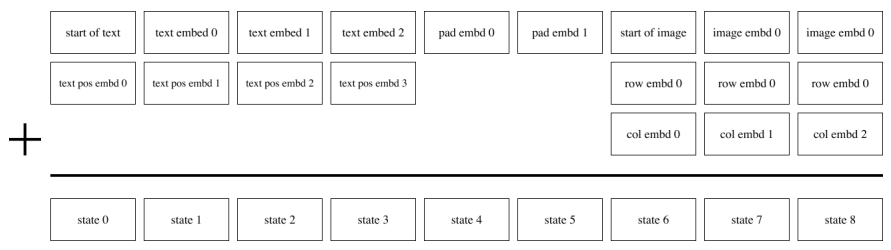
- Transformer Embedding Scheme
GPU Efficiency
- Mixed-Precision Training
- 대규모 모델을 학습할 때, GPU 메모리 사용량이 매우 커질 수 있습니다. 이를 해결하기 위해, 32-bit(일반적인 학습에서 사용되는 정밀도) 대신 16-bit 정밀도를 사용
- 일반적으로 16-bit 정밀도를 사용할 때, 손실 값(Loss)이 너무 작아지거나 커지는 문제를 방지하기 위해 손실 값을 스케일링하는 기술이 필요
- 표준 손실 스케일링 방법 대신, Per-resblock gradient scaling이라는 방법을 사용한다고 설명
- 이는 모델의 각 Resblock(Residual block)마다 독립적으로 그래디언트의 스케일링을 적용하는 방법입니다. 이렇게 하면 학습이 더 안정적으로 이루어질 수 있음
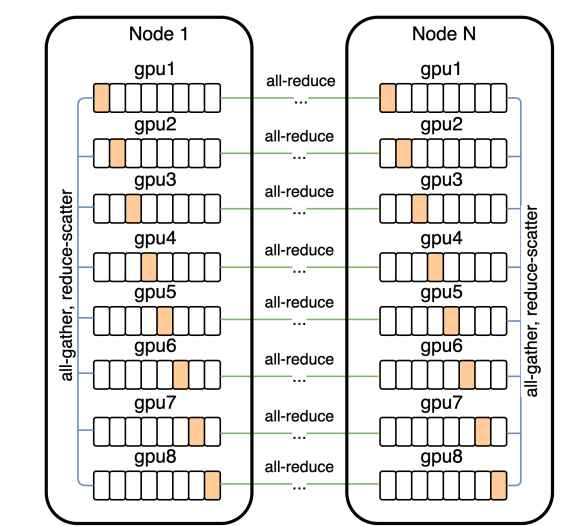
- Distributed Optimization
- DALL-E 모델은 120억 개의 파라미터를 가진 매우 큰 모델
- 이 모델을 학습하기 위해서는 대용량의 GPU 메모리가 필요하며, 16-bit 정밀도를 사용하면 이 모델이 24GB의 메모리를 차지하게 됨
- 분산 학습에서 여러 노드(GPU나 서버)들이 함께 학습을 진행하는 경우, 노드들 간에 그래디언트(Gradient)를 주고받아야 함
- 이 과정에서 많은 데이터가 전송되는데, 이는 통신 병목을 일으킬 수 있음
- PowerSGD는 이 그래디언트를 압축하여 통신 부담을 줄이는 방법

Reference