[X:AI] BLIP 논문 리뷰
Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
논문 원본 : https://arxiv.org/abs/2201.12086
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has bee
arxiv.org
3. Method
3.1 Model Architecture
- Unimodal Encoder, Image-grounded Text Encoder, Image-grounded Text Decoder로 구성
Unimodal Encoder
- Image와 Text 데이터를 별도로 인코딩
1) Image Encoder
- ViT를 사용하여 입력 이미지를 patch로 나누어 임베딩 (Object Detector보다 계산 효율적)
- Global Image Feature를 표현하기 위해 [CLS] 토큰 사용
- [CLS] 토큰 : 입력 시퀀스의 맨 앞에 위치하며, 입력 전체를 대표하는 벡터로 학습됨
2) Text Enocder
- BERT와 같은 구조
- 입력된 문장을 토큰화하고 임베딩
- 텍스트의 시작 부분에 [CLS] 토큰이 추가되어 문장의 전체 의미 표현
Image-grounded Text Encoder
(Transformer Block 내의 구조)
- Self-Attention Layer : 일반적인 Transformer에서 사용되는 Self-Attention layer는 입력된 텍스트 토큰들 간의 상관관계를 학습하여 문장 내 단어들의 연관성 파악
- Feed-forward Network : Self-Attention layer 다음에 위치하는 네트워크로, 각 단어의 임베딩 벡터를 비선형적으로 변환하여 모델의 표현력을 향상시킴
(Croos-Attention Layer의 추가)
- Self-Attention과 Feed-forward layer 사이에 삽입
- Text Encoder가 Image Enocder의 정보를 참조할 수 있도록 함
- 이 layer를 통해 텍스트와 이미지의 상관관계를 학습하고, 텍스트가 이미지와 어떻게 연결되는지 모델이 이해할 수 있게 함
([Encode] 토큰 사용)
- Text Encoder 입력에 [Encode] 토큰 추가
- 해당 토큰의 임베딩은 Image-Text Pair의 Multimodal Representation으로 사용
Image-grounded Text Decoder
- Decoder는 텍스트 생성 작업에서 사용되며, 이미지에서 얻는 정보를 바탕으로 텍스트 시퀀스를 단계별로 생성
- Bidirectional Self-Attention Layer를 Causal Self-Attention Layer로 대체하여 현재 시점까지의 단어들만 참조하도록 하여, 미래의 단어를 참조하지 않도록 함
- [Decode] 토큰 : 텍스트 시퀀스의 시작을 알리는 역할
- [EOS] 토큰 : 시퀀스의 끝을 알리는 역할

3.2 Pre-training Objectives
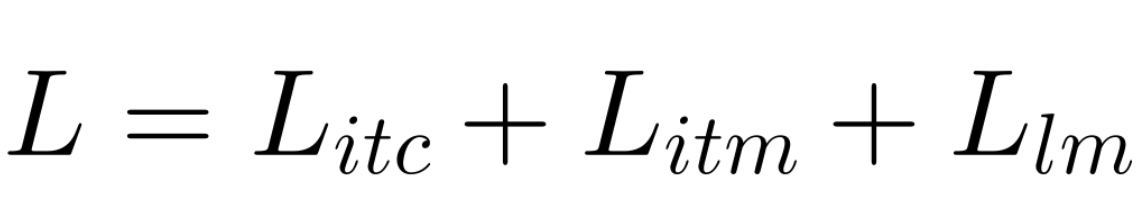
Image-Text Contrastive Loss (ITC)
- Unimodel Encoder 활성화 (각 모달리티의 표현을 더 잘 학습하게 만듦)
- Positive Image-Text Pair, 즉 서로 일치하는 이미지와 텍스트 쌍이 유사한 표현을 갖도록 유도
- 이는 Visual Transformer와 Text Transformer의 Feature Space를 align하는 것을 목표로 함
- ALBEF 모델의 Litc를 따르며, Momentum Encoder를 도입해 feature 생성
- Momemtum Encoder는 모델이 학습하는 동안 Negative Sample에서 Pontential Positive를 설명하기 위해 Soft Label를 생성 (Soft Label : 각 샘플이 Positive와 Negative 사이에 어느 정도 속하는지를 나타내는 값)
Image-Text Matching Loss (ITM)
- Iamge-grounded Text Encdoer를 활성화
- Multimodal Representation 학습 : 이미지와 텍스트 간의 세밀한 정렬을 포함하는 멀티모달 표현을 학습. 즉, 이미지와 텍스트가 함께 제공될 때, 이 둘이 의미적으로 일치하는지 학습
- ITM Head (Linear Layer) : 모델의 마지막 단계에서 사용되는 선형 레이어로, Image-Text 쌍의 멀티모달 특징을 고려하여 해당 쌍이 Positive인지 Negative인지 예측
- Informative Negative : 모델이 학습하는 동안, Negative 샘플 중에서도 특별히 중요한, 모델이 혼동할 가능성이 높은 샘플들을 선택하여 학습을 강화
- ALBEF 모델의 Hard Negative 전략을 차용하여, 실제로 일치하지 않는 샘플에서도 미묘한 유사성을 학습하도록 함
Language Modeling Loss (LM)
- Image-grounded Text Decoder를 활성화
- Text Encoder와 Decoder의 파라미터 공유 (Self-Attention layer 제외)
- 인코더와 디코더 작업 간의 차이점을 가장 잘 반영할 수 있는 부분이 Self-Attention 레이어이기 때문
- Encoder는 현재 입력 토큰에 대한 Representation을 구축하기 위해 Bi-directional Self-Attention, Decoder는 다음 토큰을 예측하기 위해 Casual Self-Attention
3.3 CapFilt
- Annotion 비용 : 고품질의 Image-Text pair를 수집하는 것은 비용이 많이 듦. 즉, 사람이 일일이 주석을 달아준 Image-Text pair의 수는 제한적
- 웹에서 자동 수집 : 최근 연구들은 웹에서 대량의 Image-Text pair를 자동으로 수집하는 방식에 집중
- 많은 수의 Image-Alt Text Pair (이미지와 그에 대한 간단한 설명) 데이터가 여기에 포함
- 문제점 : Alt Text는 이미지의 시각적 내용을 정확하게 설명하지 못하는 경우가 많음. 이러한 데이터는 Vision-Language 모델 학습에 노이즈를 유발
Captioner는 Image-grounded Text Decoder
- 주어진 이미지의 텍스트를 디코딩하기 위해 LM Objective에 따라 Fine-tuning 됨
- 웹에서 수집된 이미지(Iw)가 주어지면, Captioner는 각 이미지에 대해 하나의 캡션(Ts)을 생성
Filter는 Image-grounded Text Encoder
- ITC와 ITM Objective에 따라 텍스트 인코더가 세밀하게 fine-tuning
- 원본 웹 텍스트 Tw와 합성 텍스트 Ts 모두에서 Noise가 있는 텍스트를 제거
- 필터링 과정에서 ITM Head를 사용하여 텍스트와 이미지가 일치하지 않는 경우, 이 텍스트를 노이즈로 간주하고 제거
- 필터링을 통해 선별된 Image-Text 쌍과 사람이 직접 주석을 단 데이터 쌍과 결합
- 새롭게 형성된 고품질 데이터셋을 사용하여 새로운 모델을 사전 학습함
