[X:AI] SPPNet 논문 리뷰
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
논문 원본 https://arxiv.org/abs/1406.4729
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip th
arxiv.org
1. Abstract & Introduction
- 과거에 사용된 CNN은 고정된 입력 이미지 크기(ex. 224x224) 요구
- fully-connected layer에서 고정된 길이의 입력이 필요하기 때문
- cropping과 warping(왜곡)을 통해 다양한 크기의 입력 이미지를 고정된 크기로 변환
- cropping한 이미지는 객체 전체를 포함하지 못할 가능성이 있으며 wraping한 이미지 가로세로 비율이 달라져 객체의 본질적인 특징을 잘못 학습할 가능성이 높음

- 본 논문은 SPP layer을 도입하여 'CNN이 고정된 크기의 입력 이미지를 받아야 한다'는 제약조건 해결
- SPP (Spatial Pyramid Pooling) layer를 conv layer와 fc layer 사이에 배치
- SPP는 가변 크기의 입력 이미지를 고정된 길이의 벡터로 변환하여 fc layer에 전달할 수 있도록 함
- 이에 따라 입력 이미지를 따로 cropping, warping 할 필요 없이 네트워크가 다양한 크기의 입력을 처리할 수 있음

2. Deep Networks With Spatial Pyramid Pooling
2.1 Convolutional Layer and Feature Maps
- 대표적인 7층 구조의 네트워크 고려
- 해당 네트워크에서 처음 다섯 개 layer은 Conv layer이며, 일부는 Pooling layer
- 이러한 Pooling layer는 슬라이딩 윈도우 방식을 사용하기 때문에 Conv layer로 간주될 수도 있음
- 마지막 두 계층은 FC layer로 이루어져 있으며, 출력으로 N-way Softmax (N : 분류 카테고리 수)
- feature map 생성 시 입력 크기 고정할 필요 없음
- 이미지 크기에 상관없이 슬라이딩 필터를 적용해 feature map 생성
- feature map은 이미지에서 강하게 반응하는 패턴(예: 원, ∧, ∨)을 찾아내고, 그 위치 정보를 유지
- 하지만 해당 신경망은 FC layer 때문에 고정된 이미지 크기가 필요

- 전통적인 이미지 처리 방법
- 고정된 이미지 크기 입력 필요 + 학습 불가능
- 특징 추출 : SIFT, Image Patch 기법 등 사용 (사람이 설계)
- 인코딩 : Vector Quantization, Sparse Coding, Fisher Kernel 사용 (사람이 설계)
- Pooling : BoW (Bag-of-Words), Spatial Pyramid 사용 (사람이 설계)
Bow (Bag-of-Words)
- 이미지의 Region 별로 여려 개의 Feature 추출
- 미리 정해진 단어 사전처럼, 해당 특징들을 각각 코드로 바꿈
- 각 Feature 별로 이미지에서 나타나는 빈도수 count하고 히스토그램으로 표시 (고정 길이 벡터로 표현)
- 빈도수를 통한 이미지 추론

SPM (Spatial Pyramid Matching)
- 하지만 이와 같은 Bag of Words 방법은 이미지의 위치 관계를 잃어버린다는 단점 존재
- 따라서 이를 극복하기 위해 제안된 방식이 SPM
- 이미지를 여러 영역으로 분할해서 각 영역마다 BoW 적용
- ex) 아래와 같이 분할을 아예 하지 않았을 때, 4분할을 했을 때 총 2번을 수행하여 SPM 진행하고 이를 기반으로 Count한 벡터들을 하나로 결합
- SPM을 사용하게 되면 Feature Map 크기가 서로 달라도 분할 수를 동일하게 설정만 한다면 결합한 벡터들의 사이즈는 동일

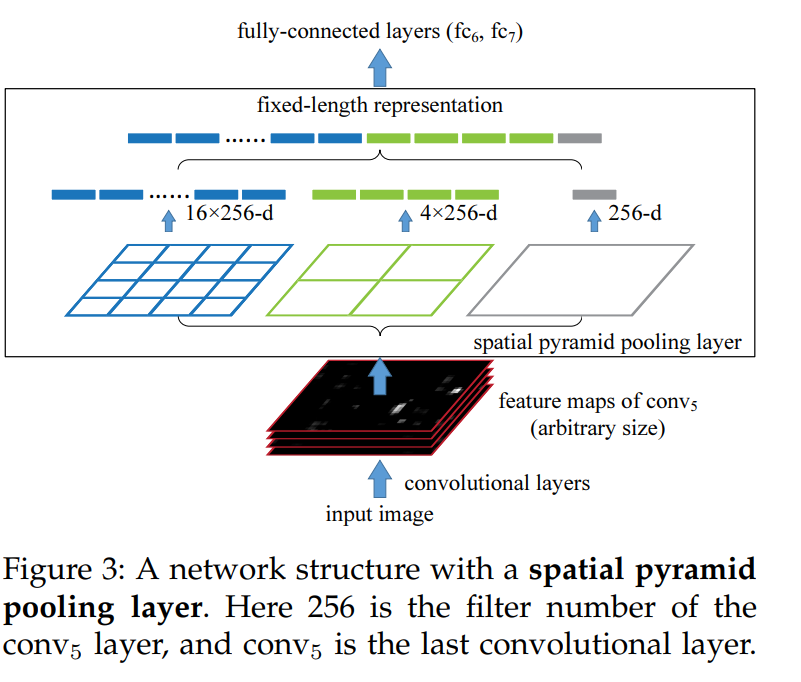
2.2 The Spatial Pyramid Pooling Layer
- Conv layer는 임의 크기의 입력을 처리할 수 있지만, 출력 결과는 크기가 가변적
- 반면, 분류기(SVM/softmax)나 FC layer는 고정된 길이의 벡터를 요구
- 고정 길이 벡터는 Bag-of-Words(BoW) 방식을 통해 생성 (하지만 한계 존재)
- 본 논문에서는 SPP (Spatial Pyramid Pooling) 사용
- Bin을 일정한 수로 고정시키고 각 영역별 최대값만 뽑아냄(Max pooling)
- Bin은 4x4, 2x2, 1x1로 21개 (M개)
- 필터는 conv5 필터 수로 256개 (k개)
- 필터 수만큼 output 채널 수가 정해짐
- SPP 결과값은 (k x M) 차원의 고정길이 벡터
- 따라서 21 x 256 = 5,376차원의 고정길이 벡터 생성
- 즉, 입력 이미지 크기와 관계없이 spatial bin 개수가 같다면, SPP layer를 통해 고정길이 벡터가 만들어짐
- 마지막 Pooling layer를 SPP layer로 대체
- Input -> Conv5 layer -> SPP layer -> FC3 layer -> Output

- conv5를 거친 feature map 크기가 (axa)이고, 만들고자하는 spatial bin 크기가 (nxn)
- 윈도우 크기 = celling(a/n)
- stride 크기 = floor(a/n)
- ex) conv5를 거친 feature map 크기가 (13x13), 만들고 싶은 spatial bin 크기 (2x2)
- 윈도우 크기와 stride 크기는 각각 7과 6으로 설정
- 3단계 pyramid ( conv5 feature map 크기 13x13)

2.3 Training the Network
- 실제로는, GPU는 고정된 입력 크기에서 더 효율적으로 작동
- 입력 이미지 크기가 계속 달라지면 GPU가 매번 다른 크기의 데이터를 처리하기 위해 추가 메모리 관리 작업이 필요해지고, 효율적인 병렬 처리가 어려움
Single-size training
- 기존 연구들처럼, 고정된 크기(224×224)로 이미지를 크롭(crop)하여 Conv layer를 학습시킴
- SPP layer 적용 (사전 계산된 pooling 크기 사용)
- 이후 FC layer 학습
Multi-size training
- 예시로 224x224 크기의 이미지를 180x180으로 resize
- SPP의 출력 길이는 224x224 네트워크와 동일하도록 설계
- 두 네트워크(180과 224)는 동일한 파라미터를 공유
- 한 네트워크로 전체 epoch를 학습한 뒤 다른 네트워크로 전환
- 이러한 방식을 반복하며 학습
3. SPPNet For Image Classification
3.1 Experiments on ImagNet 2012 Classification
- 단일 크기 학습: SPP를 사용한 모델이 기존 모델 대비 1.65% 정확도 개선
- 다중 크기 학습: 224×224와 180×180 두 크기를 번갈아 학습해 정확도 추가 개선(최대 2.33% 향상)
*top-1 error : 모델이 가장 높은 확률을 갖는 단일 클래스를 올바르게 예측하지 못하는 비율
*top-5 error: 모델이 상위 다섯 개의 확률이 가장 높은 클래스 중에 올바른 클래스를 예측하지 못하는 비율

3.2 Experiments on VOC 2007 Classification
- SPP를 활용한 전체 이미지 표현(full-view representation)으로 정확도 향상(78.39% vs. 76.45%)

3.3 Experiments on Caltech101
- SPP-net이 기존 네트워크(no-SPP)보다 높은 정확도(91.44%)를 기록
- 전체 이미지 표현(full-view)이 크롭(crop)된 이미지보다 더 나은 성능
- 이미지 왜곡(warping)을 최소화한 방법이 더 우수한 결과를 보임

4. SPPNet For Object Detection
기존 R-CNN의 한계
- region proposal network를 통해 약 2000개 ROI(Region of Interest) 추출
- ROI들이 독립적으로 CNN에 입력 -> 너무 느림

SPPNet의 개선점
- 전체 이미지에 대해 CNN 수행
- Region Proposal은 원본 이미지에서 추출하여 feature map에 사영
- RCNN 2000번 -> SPPNet 1번의 CNN operation 절감효과
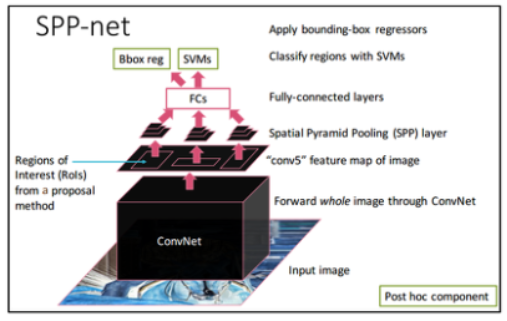
4.1 Detection Algorithm
- 후보 영역 생성
- Selective Search의 "fast mode"를 사용하여 약 2000개의 후보 영역 생성
- Feature 추출
- 이미지를 특정 크기(예: s=688)로 리사이즈 후, CNN으로 feature map을 추출
- 후보 영역마다 SPP(4-level pyramid: {1×1, 2×2, 3×3, 6×6, 총 50 bins})를 적용해 고정 길이(12,800차원)의 feature 벡터 생성
- 분류(SVM)
- 각 후보 영역의 feature를 사용해 이진 SVM으로 물체 여부를 판별
- 후처리
- Non-Maximum Suppression(NMS)을 통해 중복되는 후보 영역 제거
- Bounding Box Regression을 적용해 예측 경계를 정교화
4.2 Detection Results & 4.3 Complexity and Running Time
- Pascal VOC 2007
- SPPNet은 R-CNN과 비슷하거나 더 나은 정확도(mAP)를 달성
- SPPNet 5-scale mAP: 59.2%
- SPPNet 1-scale은 R-CNN보다 270배 빠르게 동작
- SPPNet(1-scale): 0.053초/이미지
- R-CNN: 14.37초/이미지
- SPPNet은 R-CNN과 비슷하거나 더 나은 정확도(mAP)를 달성

4.4 Model Combination for Detection
- 서로 다른 초기화로 학습된 모델을 조합해 추가 성능 향상(최대 60.9% mAP)

4.5 ILSVRC 2014 Detection
- ILSVRC 2014
- Single Model: 31.84% mAP
- 6개의 모델 조합 후: 35.11% mAP (경쟁 결과 중 2위 기록)

5. Conclusion
- 이전 CNN 기반 모델들은 Input 시 이미지 크기를 고정해야했기에 이미지 스케일이나 비율을 유연하게 다룰 수 없었음
- 본 논문에서 SPP 기법을 제시하여 다양한 크기의 Input 값으로부터 고정된 크기의 feature vector를 뽑아냄
- 이미지 전체에 대해 Convolution 연산을 수행하여 Object Dection 분야의 선행 모델인 R-CNN보다 속도가 빠름
[참고자료]
https://woochan-autobiography.tistory.com/919
https://89douner.tistory.com/89
https://rahites.tistory.com/78