논문 원본 : https://arxiv.org/abs/2307.10638
Quantized Feature Distillation for Network Quantization
Neural network quantization aims to accelerate and trim full-precision neural network models by using low bit approximations. Methods adopting the quantization aware training (QAT) paradigm have recently seen a rapid growth, but are often conceptually comp
arxiv.org
Abstract & Introduction
- 신경망 양자화(Neural network quantization)는 저비트 근사치를 사용하여 완전 정밀(Full Precision, FP) 신경망 모델을 가속화하고 경량화하는 것을 목표로 함
- 최근 QAT 패러다임을 채택한 방법들이 빠르게 발전하고 있지만, 개념적으로 복잡한 경우가 많음
- 본 논문은 참신하고 매우 효과적인 QAT 방법인 Qauntized Feature Distillation(QFD)를 제안
- QFD는 먼저 양자화된 표현을 교사(teacher)로 학습한 뒤, 지식 증류(KD, Knowledge Distillation)를 사용하여 네트워크 양자화
- 정량적 결과에 따르면, QFD는 기존 양자화 방법보다 더 유연하고 효과적이며 단순함


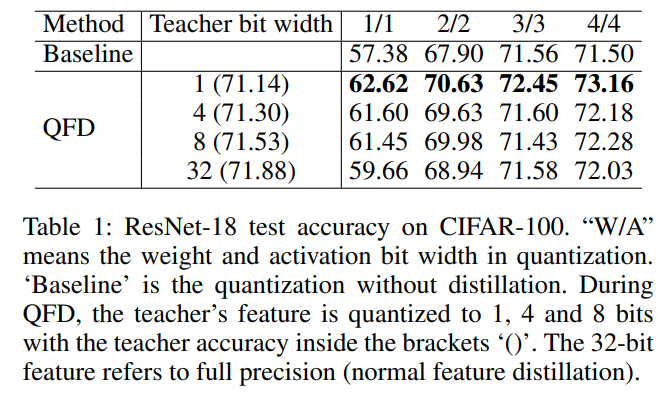
The Proposed Method
Preliminaries
- Lee, Kim, and Ham(2021)의 방법을 기준 방법으로 채택
1) 정규화 단계
- 주어진 숫자를 0~1 범위로 스케일링
- v : 원래 숫자 (모델의 가중치나 활성화 값)
- l, u : 숫자의 최소값과 최대값 (양자화 간격)
- clip : 값이 0보다 작으면 0, 1보다 크면 1로 제한

2) 양자화 단계
- 정규화된 숫자를 고정된 비트 수로 표현되는 이산 값으로 변환

3) 비양자화 단계
- 양자화된 숫자를 원래 값에 가깝게 재조정

4) 학습 가능한 스케일 파라미터 α
- 활성화 값에 곱해지는 학습 가능한 파라미터로, 모델이 더 유연하게 학습할 수 있도록 도와줌
5) 훈련 중 기법
- Straight Through Estimator (STE)

- 동시에 학습되는 가중치와 양자화 파라미터
- 모델의 가중치와 양자화 파라미터는 역전파를 통해 동시에 학습됨
Quantized Feature Distillation
- 입력 이미지 I를 두 개의 네트워크에 각각 전달
Teacher Network
- 완전 정밀(Full Precision) 모델로, 고품질 특징 ft를 추출 (GAP 사용)
- 이 특징은 양자화되어 낮은 비트로 변환
Student Network
- 양자화된 모델로, fs라는 특징 벡터를 생성
- 이 네트워크는 학습 중이며, 교사 네트워크로부터 도움을 받음
- 교사 네트워크가 생성한 양자화된 특징(ft)을 학생 네트워크가 따라하도록 학습
- 이를 위해 Mean Squared Loss(L)을 사용하여 fs와 ft의 차이를 최소화
- 동시에 학생 네트워크는 Cross Entropy Loss(H)를 통해 예측 정확도를 높이는 학습도 병행
최적화 수식
- : 두 손실 간의 중요도를 조정하는 하이퍼파라미터 (기본적으로 λ=0.5 설정)
- L(fs,ft) : 교사와 학생의 특징 차이를 줄이는 Mean Sqaured Loss
- H(y,ps) : 학생의 예측값 ps와 실제 정답 y를 비교하는 Cross Entropy Loss





